Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past.
Multivariate normal distribution arises in many aspects of mathematical statistics and machine learning. For instance, Cochran's theorem in statistics, PCA and Gaussian processes in ML heavily rely on its properties. Thus, I'll discuss it here in detail.
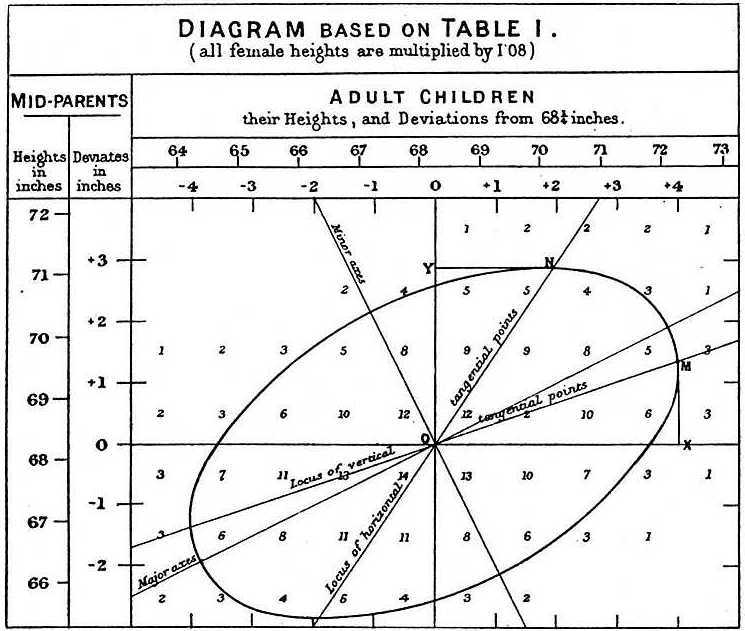
Heights of 205 parents and 930 adult children, from “Regression towards mediocrity in hereditary stature” by F.Galton, 1886
Heights of parents were normally-distributed, as well as the heights of their children. However, the distributions were
obviously not independent, as taller parents generally give birth to taller children. Probably, this plate is one of the first depictions of 2-variate normal distribution’s isocontour. As a side note,
Galton has also come up with the ratio of male to female heights here, which is 1.08 (according to the modern data, it is closer to 1.07).
Galton actually rediscovered the concept of correlation two years after this paper, in 1888.
Multivariate normal distribution
A random vector X=[x1,x2,...,xn]T is called multivariate normal distribution, if each dimension of it represents a one-dimensional normal distribution.
They write X∼N(μ,Σ), where μ=[μ1,μ2,...,μn]T is a vector of means, and the elements of matrix Σ are covariances between pairs of individual coordinates (xi, xj):
What is the meaning of covariance matrix and what does it do in the probability density function of multivariate normal?
Square root of a quadratic form (X−Y)TΣ−1(X−Y), where Y and X are n-vectors and Σ is an n x n matrix, is
called Mahalanobis distance between vectors X and Y.
If the matrix Σ is a unit matrix, e.g. I=⎝⎛100010001⎠⎞, Mahalanobis distance is the same as Euclidean.
However, if the coordinates of the vector X are strongly correlated, Mahalanobis distance could be much more helpful to e.g. detect outliers.
For instance, imagine, that your vector X contains flat properties: (x1 = total_area, x2 = living_rooms_area, x3 = distance from center).
You can tell that total flat area and living rooms area have a reasonably strong correlation (as an edge case they could completely duplicate each other).
For instance, here is a possible covariance matrix for your flat’s properties Σ=⎝⎛10.70.10.710.20.10.21⎠⎞, Σ−1=⎝⎛1.967−1.3930.082−1.3932.029−0.2660.082−0.2661.045⎠⎞.
The key to understanding the covariance matrix is analysis of its eigen decomposition. Let E be the matrix of eigenvectors of Σ, let Λ be the diagonal matrix of eigenvalues of Σ.
Covariance matrix is symmetric (and positively semi-definite). For a symmetric matrix, its eigenvectors are orthogonal (so that inverse matrix of an orthogonal matrix is its transpose): Σ=EΛE−1 => ΣT=(E−1)TΛTET=EΛE−1=Σ.
ΛT=Λ, thus, E−1(E−1)TΛETE=Λ, indicating that ETE=I, or E is orthogonal.
So the logic of Mahalanobis distance can be seen as follows: (X−Y)TΣ−1(X−Y)=(X−Y)TEΛ−1ET(X−Y).
By multiplying X−Y by the inverse/transposed eigen matrix ET (and doing the same in transposed way to the left side from Λ−1, when multiplying (X−Y)TE), we de-correlate the dimensions of the vectors, transforming those inter-dependent factors into orthogonal, independent.
Then we take the sum of squares of those de-correlated factors, but a weighted one, we give some dimensions more weight then the others, by multiplying by the matrix of eigenvalues Λ.
Let us show that correlated vectors, multiplied by ET, become uncorrelated. If eigenvector Ei had coordinates ⎝⎛ei,1ei,2ei,3⎠⎞, then:
First, we used the fact that covariance of a linear combination of random variables is a linear combination of covariances. Then we used the fact that E1 is the eigenvector of matrix Σ, and ΣE1=λ1E1. Lastly, we used the fact that eigenvectors E1 and E2 are orthogonal, and their dot product is 0.
Now, as you can see, the power of exponent in multivariate normal distribution, is the square of Mahalanobis distance between the vector and its mean, divided by 2.
So, it works in the same way, it converts our correlated factors into uncorrelated ones, and takes sum of their squares, weighted by eigenvalues of respective directions.
This also explains, why the denominator contains ∣det(Σ)∣: the eigenvalues of the covariance matrix are the elements of diagonal matrix Λ, which are the variances of de-correlated normal distributions.
By Binet-Cauchy formula the determinant of det(Σ)=det(Λ). Thus, by normalizing the probability density function by ∣det(Σ)∣,
we do the same as by normalizing pdf of one-dimensional normal distribution by σ2.
Uncorrelated multidimensional normal variables are independent
This property of multidimensional normal distribution is fairly obvious from the previous property.
Thus, we can see that uncorrelated dimensions of random vector can be factored-out into independent random variables.
Marginalization and Conditioning
Marginalization
You marginalize multivariate normal distribution by taking an integral over 1 of its dimensions.
For instance, if you integrate Galton’s 2-variate normal distribution over the heights of all the fathers, you get 1-dimensional distribution of heights all the children.
Conditioning
You do conditioning, when you fix the value of one dimension of multivariate normal distribution and achieve a lower-variate one.
For instance, you can choose fathers, who are x2 inches tall, and achieve the conditional distribution of
heights of their children, which is one-dimensional normal:
Note that the mean and variance of this distribution differ from the marginalized one - children of taller fathers are, obviously, taller.
Quadratic forms, their ranks and special cases of quadratic forms
The power of exponent of p.d.f. of a multivariate normal 2(X−μ)TΣ−1(X−μ) is a quadratic form.
Speaking of the matrix Σ, there is a useful concept of matrix rank, which is the number of linearly independent rows/columns in the matrix.
For instance, if our quadratic form is just a product of two vectors (a1x1+a2x2+a3x3)(b1x1+b2x2+b3x3), the rank equals 1, because all the rows are linearly dependent.
Indeed, we could see this, when we write the product in matrix notation:
The multiplication of row-vector by column-vector in linear algebra is called dot product, or inner product:
(x1x2x3)⋅⎝⎛a1a2a3⎠⎞=a1x1+a2xx+a3x3.
Less commonly used, the multiplication of columns-vector by row vector is called an outer product, and it results in a matrix, where each element is a product of respective elements of column-vector and row-vector:
If you choose the latter way, it becomes obvious that the rank of matrix
⎝⎛a1b1a2b1a3b1a1b2a2b2a3b2a1b3a2b3a3b3⎠⎞
, formed by an outer product of coefficients a and b, equals 1.
Indeed, its i-th row is a multiple of ai by row-vector bT=(b1b2b3), so
all the rows differ just by a scalar ai, so there is just 1 linearly independent row.
If we chose a real-life covariance matrix (10.50.51), it is clear that its rank equals 2, so it cannot be represented as (a1x1+a2x2)(b1x1+b2x2).
Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram