

Johnson-Lindenstrauss lemma
September 10, 2021 14 min read
Johnson-Lindenstrauss lemma is a super-important result on the intersection of fields of functional analysis and mathematical statistics. When you project a dataset from multidimensional space to a lower-dimensional one, it allows you to estimate, by how much you distort the distances upon projection. In this post I work out its proof and discuss applications.
Proof intuition
The logic of Johnson-Lindenstrauss lemma is as follows: suppose that we have points in a -dimensional space.
Let us sample -dimensional gaussian random vectors (a gaussian random vector is such a vector, that each coordinate of it is standard gaussian distributed:
Then it turns out that if we were to project any -dimensional vector on a lower-dimensional (i.e. -dimensional) basis, constituted by those gaussian vectors, the projection would preserve the length of that vector pretty well (the error in it decays very fast with increase in dimensionality of this lower-dimensional space). Moreover, the projection would also preserve the distances between vectors and angles between them.
How so? This follows from the fact that the error in length, introduced by a random projection, has our good old Chi-square distribution, and we already know that its tails decay very fast.
The structure of the proof is as follows:
-
You’ll have to trust me on the fact that the length of the random projection is Chi-square-distributed. I’ll show that probability that , where is a small number, decays at least exponentially with the growth of fast after it passes its mean (lemma on bounds of Chi-square).
-
Then I’ll show that the length of random projection vector is indeed Chi-squared-distributed, and, thus, projection operation preserves the length of vector x, i.e. with arbitrarily high probability.
-
Then I’ll finally derive the Johnson-Lindenstrauss theorem from the norm preservation lemma.
-
As a bonus I shall prove that not only norms/lengths are preserved by random projections, but inner products/angles as well.
Lemma (on bounds of Chi-squared distribution tails)
We need to show that the error in distances estimation in the projection space decreases at least exponentially with the increase of dimensionality of projection space - i.e. the number of degrees of freedom of our distribution:
for a reasonable small relative error , and we know that the expectation . So, we want to show that probability that Chi-squared distributed variable exceeds its expectation by, say, 10% of is rapidly decaying with growth of .
It is intuitive from the look at the p.d.f of Chi-squared distribution plot that chi-squared probability density function’s maximum is located before its mean , so by the time it reaches the mean , it is already decreasing. The question is: is it decreasing fast enough - i.e. exponentially?
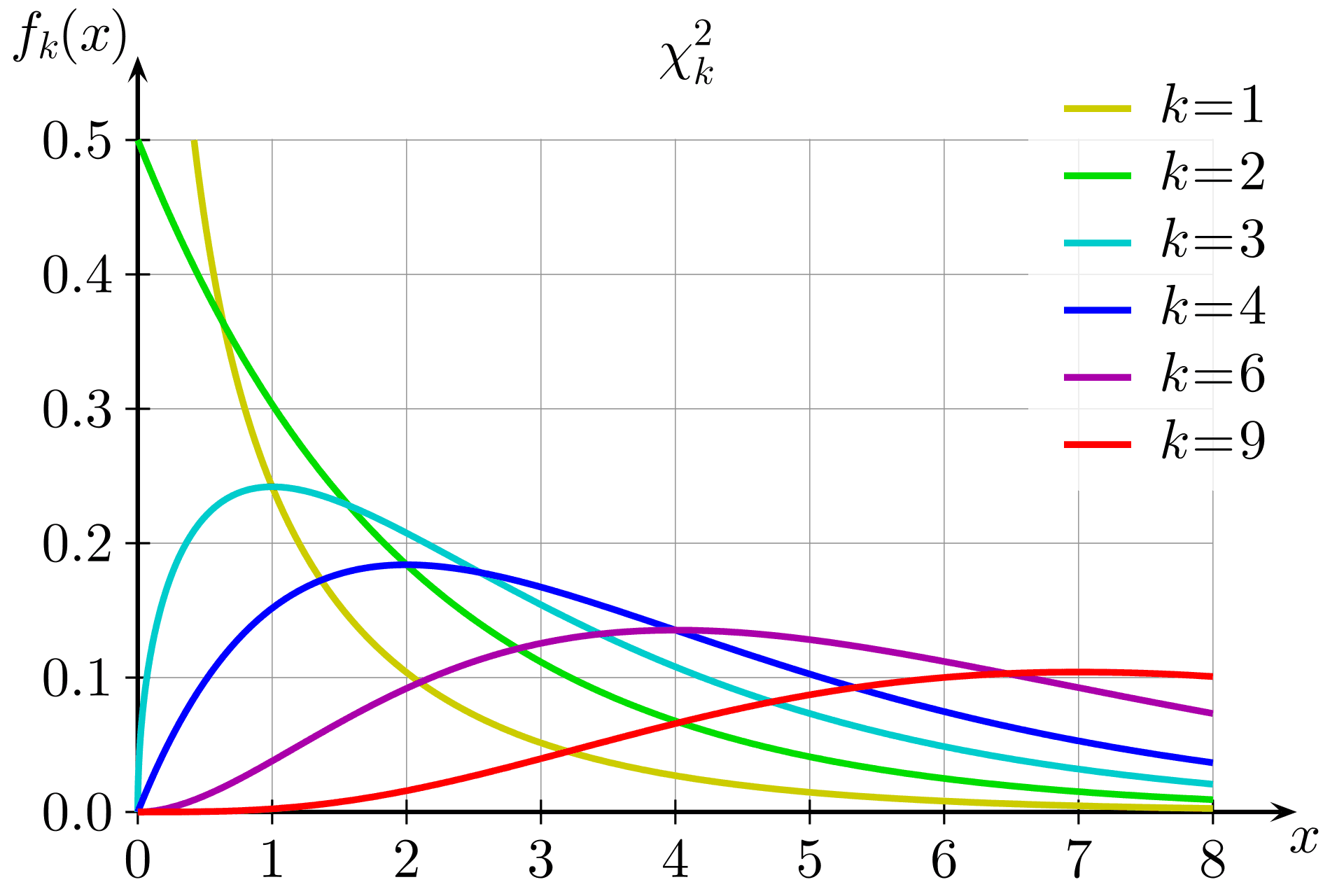
Gamma function (essentially, for even ) in the denominator of p.d.f. grows faster than in the numerator starting from some large enough , giving at least an exponential decay on . This follows from Stirling formula: - obviously, outgrows . So, at least for large values of relative error our statement holds.
Now, we need to prove it for small errors . What do we do?
Well, the inequality definitely rings a bell. Recall the Markov inequality (a.k.a. Chebyshev’s first inequality in Russian literature):
Unfortunately, its direct application to a chi-square distributed variable doesn’t help, but if we do some tricks with it, we’ll get what we want.
We will potentiate both sides of inequality and introduce a parameter , which we’ll evaluate later. This technique is called Chernoff-Rubin bound:
The right side is minimized upon :
Hence, .
Now, use Taylor expansion of and exponentiate it to get: .
The proof is analogous for the other bound .
Norm preservation lemma
Recall that is our d-by-k matrix of random vectors, forming our projection space basis.
Given the results of lemma on chi-squared tails, we shall be able to estimate the probability that the length of a single point is estimated correctly by a random projection, if we manage to prove that is a Chi-square-distributed random variable. Then this result will follow:
So, how to show that ?
First, note that in the projection vector each coordinate is a weighted sum of gaussian random variables and is itself a gaussian random variable.
Its expectation is, obviously, 0. Its variance, however, is unknown. Let us show that it is 1:
,
where are individual standard normal random variables that are the elements of matrix A.
Now, if we sum over coordinates of the projection vector, we get the desired result:
.
Johnson-Lindenstrauss theorem
Johnson-Lindenstrauss theorem follows from the norm preservation lemma immediately.
If you have points, you have distances between them (including distance from a point to itself). The chance that none of the distances is wrong, thus, is
.
Thus, you need to keep this probability as small as you prefer, where is some constant.
Bonus: inner product (angles) preservation
Norm preservation lemma above guarantees not only preservation of distances, but of angles as well.
Assume that and are two vectors, and and are their random projections. Then:
Subtract one inequality from the other (note that this leads to inversion of sides of double inequalities in the subtracted inequality):
So, as a result we get: with probability or higher.
Not only Gaussian
Here we used gaussian random variables as elements of our random projection matrix , followed by analysis of Chi-squared distribution.
But note that when the number of degrees approaches 100, Chi-square converges to Gaussian very closely, and relative error near mean is decaying as an exponential function of as increases. Seems like the convergence rate of central limit theorem could be a valuable tool here for other distribution types.
So in that regard it doesn’t make much difference, which random variables we take as elements of , Gaussian or not. Another purpose Gaussians served here, was their useful property that a weighted sum of Gaussian random variables is Gaussian itself, which might not be the case for other distributions. But as soon as this property holds, we can use other distribution types for random projections.
There is a natural way to define a subset of distributions that would fit: a distribution is called sub-Gaussian with a parameter , if for all real . As you recall, we used this in our Chernoff bound. A popular alternative is to use Bernoulli random variables with random signs {-1, 1} instead.
Tightness of estimate
Throughout 2014-2021 in a series of papers Larson and Nelson and Alon and Klartag (see references) showed that the bound , given by Lindenstrauss-Johnson is optimal for any linear or even non-linear projection.
The papers are fairly technical, they employ approaches from classical functional analysis (like coverages with balls and Minkowski functional) and coding theory (such as Reed-Solomon codes). See references section.
Applications
Manifold learning/multidimensional scaling
Johnson-Lindenstrauss suggests a way to look at your t-SNE/UMAP plots. As 2D or 3D is definitely not enough for an accurate depiction of the multidimensional distances, don’t trust them in your plots.
Statements like “point B is 2 times farther from point A than point C” make no sense - the distances could’ve been distorted and with different parameters of the projection you might get a picture, where point C is 2 times farther form point A that point B.
The only thing you can more or less trust in t-SNE is the notion of neighbourhood: if points A and B are very close on t-SNE plot, they are very close in the original multidimensional space. As an example, see a recent crusade of the adorable Lior Pachter against t-SNE and UMAP.
Rule of thumb for an autoencoder latent space
If you’re not sure about the dimensionality of the latent space of your autoencoder, such as VAE, Johnson-Lindenstrauss suggests that is a good rule of thumb. It is small enough and preserves distances well enough.
Compressed sensing
Johnson-Lindenstrauss provides an excellent intuition on how to achieve a sparse space in compressed sensing. I’ll dedicate a whole separate post to this beautiful mathematical theory.
References
- https://home.ttic.edu/~gregory/courses/LargeScaleLearning/lectures/jl.pdf - proof outline number 1
- https://cseweb.ucsd.edu/~dasgupta/papers/jl.pdf - proof outline number 2
- https://en.wikipedia.org/wiki/Johnson%E2%80%93Lindenstrauss_lemma
- http://www.cs.cmu.edu/afs/cs/academic/class/15750-s19/OldScribeNotes/lecture23.pdf - a good overview of the state of the field, generalizations and recent results
- https://arxiv.org/pdf/1610.00239.pdf - Alon and Klartag paper on JL optimality
- https://arxiv.org/pdf/1411.2404.pdf, https://cs.au.dk/~larsen/papers/jl_transform.pdf - Larsen and Nelson paper on proof of optimality of JL for linear maps
- https://arxiv.org/pdf/1609.02094.pdf - Larsen and Nelson paper with proof of optimality of JL estimate for any map
- https://arxiv.org/pdf/2107.06626.pdf - most recent Larsen paper on JL optimality

Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram