

Economic Complexity Index (ECI)
November 11, 2022 12 min read
The death of globalism in 2022 brings all kinds of economic sanctions. Lately I've been running into the term Economic Complexity Index (ECI), which reflects the diversification of exports of a country. In this post I investigate the mathematics behind it and draw connections to the problems of Ncut, biclustering etc.
Economic complexity index is often used to describe diversification of a country’s exports. Usually countries with highly diversified exports also produce a multitude of technologically advanced products and thus are more self-sustained (although they might be highly dependent on imports of commodities from countries, lagging behind in technology).
For comparison, Japan and Germany are among the world leaders in OEC, being No. 1 and No. 4 with ECI=2.19 and ECI=1.88 respectively. The US has ECI=1.56, the UK has ECI=1.42. China has ECI=0.96, which means that it has an average level of economic complexity. Russian and Ukraine have ECI=0.5.
China has a relatively low ECI of 0.96, approximately 2 times lower than the US. This is a very low for the 1st economy in the world, which is counterintuitive. I decided to dig into the meaning of this number and to check, if it accurately represents the degree of autonomy of the Ukrainian economy.
Economic Complexity Index construction
In order to define ECI first we need to define a country-product matrix . Each element of this matrix corresponds to a so-called Revealed Competitive Advantage (RCA) of the country in producing a product :
E.g. if we have just 2 countries and just 3 products, we shall have a 2-by-3 country-product matrix:
Revealed Competitive Advantage (Balassa index)
Revealed Competitive Advantage (RCA), also known as Balassa index, works as follows. Suppose that each product were exported by each country uniformly. Then the fair share of exports of e.g. oil by every country would’ve been 13% of its total exports. However, for some countries like Russia or Norway oil constitutes 30% of exports, meaning that the share of oil in their exports is more than fair and their RCA in oil is very high:
We define a discretized country-product matrix as follows: for every product and every country we set the value of country-product matrix to 1, if country exports more than a fair share of this good, and 0, if less than fair share:
Note that many countries will have in oil (e.g. Russia, Saudi Arabia, UAE, Iraq, Iran, Norway, Canada, US, Venezuela etc.), while a very short list of countries will have in 7 nm semiconductors (US, Taiwan, South Korea).
Thus we can define two more entities, product ubiqity and economic complexity:
Product ubiquity is .
Economy complexity is .
Oil is a pretty ubiquitous product (or commodity, as people often call those), as . 7 nm chips are not very ubiquitous products, as for them, their market is an oligopoly.
Now, if a country exports a broad range of products, its economic complexity is high (e.g. for Germany, which manufactures all kinds of nuts-and-bolts, machines, pharmaceuticals etc.). If a country exports a bulk of one good (e.g. just oil), its economic complexity is low.
If we were to sort the countries in our discretized country-product matrix by economic complexity and products by product ubiquity, we’d find out that the matrix tends to have an almost triangular shape (e.g. countries with smalller economic complexity tend to export commodities):
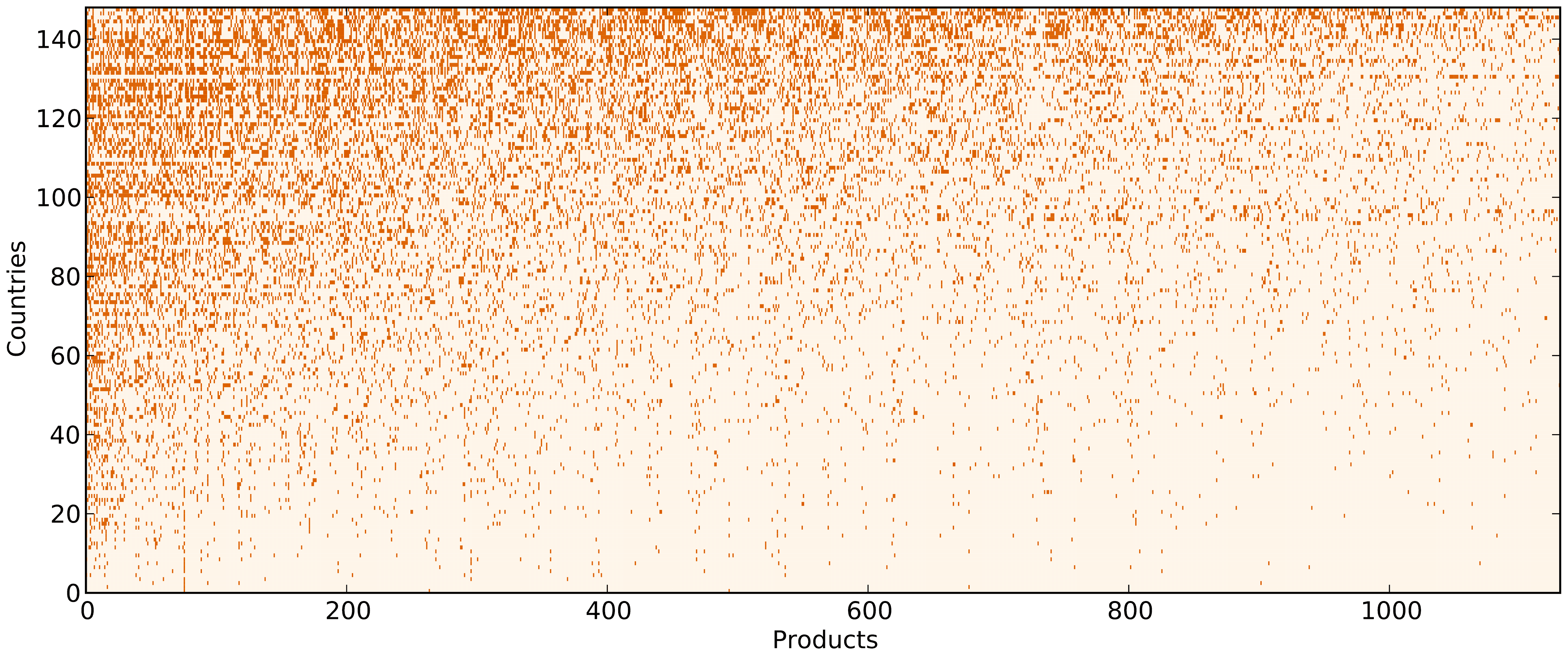
Iterative definition of ECI and PCI
Now we can finally define the Economic Complexity Index (ECI) and Product Complexity Index (PCI).
The process of definition is iterative. We introduce the notions of product ubiquity and diversification of economy as a series of iterative approximations.
Initially we start by defining all the product ubiquity and all the economies diversifications and then iteratively update vectors of economy competitiveness and product complexity according to the following formula:
After a number of iterations our process will converge to some and .
Do you sense some linear algebra in this process? If we were to define vectors and (where and are total numbers of countries and products respectively), we can feel that and are some kind of main eigenvector.
Definition of ECI/PCI through eigenvectors
Re-write the definitions of and in matrix/vector form.
To do this, we need to define two diagonal matrices of country-by-country dimensionality, and product-by-product dimensionality , which are used for normalization.
Then our iterative definition takes form:
Substituting the equations, we get a recurrent formula:
At we come to an eigenvector-eigenvalue equation:
There are many eigenvalues and eigenvectors, which work as the solution. The main eigenvalue equals 1, the matrix is stochastic, and the main eigenvector is . Therefore, we are interested in the eigenvector, corresponding to the second-largest eigenvalue.
Hence, ECI of a country is the -th coordinate of our second main eigenvector .
Similarly, PCI of product corresponds to , where .
With PCI and ECI as sorting functions, we get a similar “triangular” structure of country-product matrix:
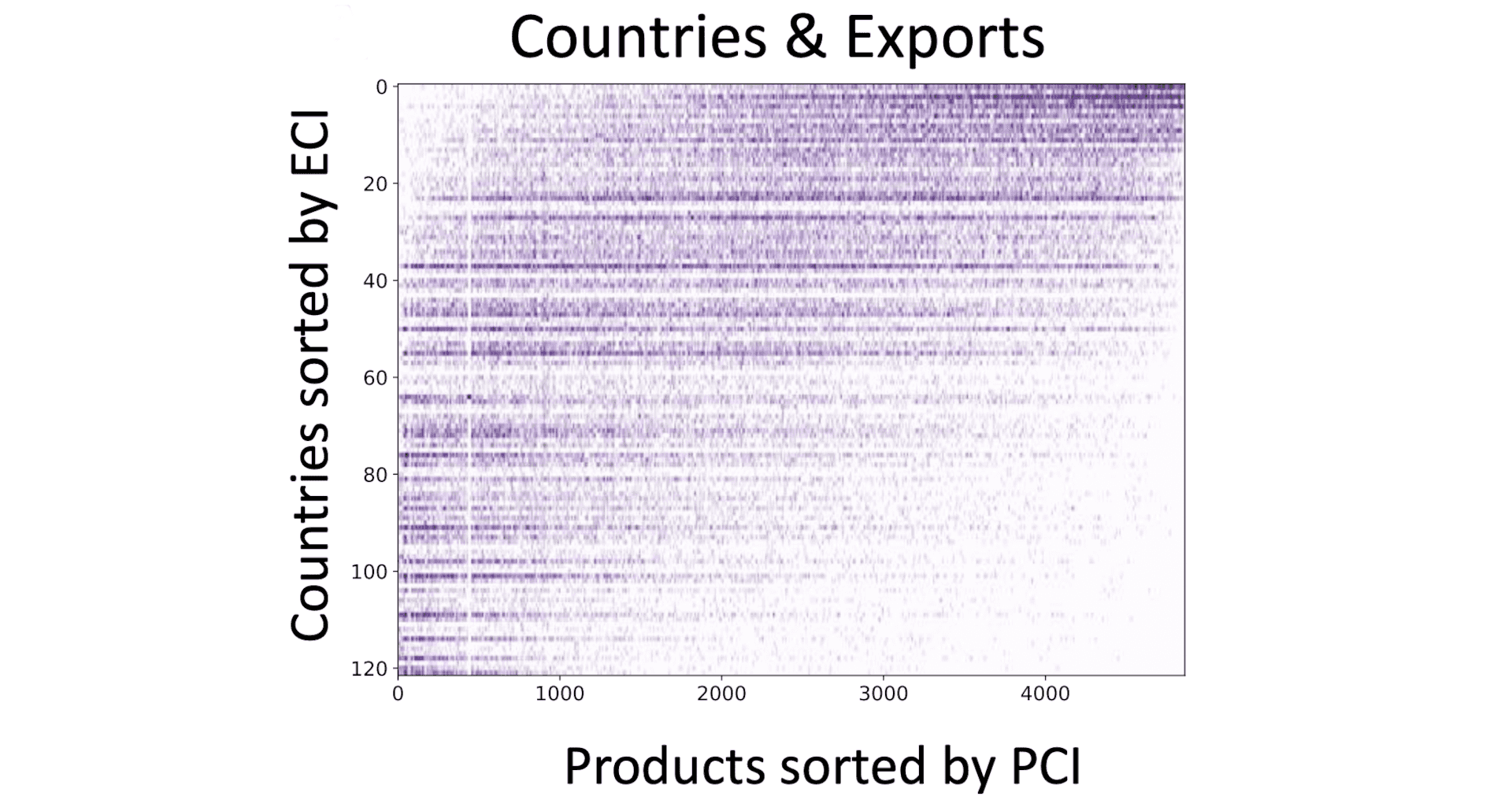
Correspondence between ECI and normalized cut algorithm
Reminder: Normalized Cut
In my previous post I looked into the Normalized Cut algorithm in detail (including its connections to the biclustering problem in bioinformatics, detection of dense subset of a bipartite graph, NMF, k-means etc.). Basically, if finds a minimal cut in a graph, such that the volumes of 2 subsets, it splits the graph into, are balanced.
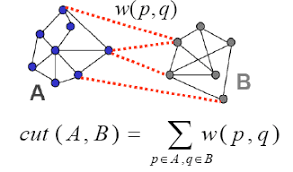
The Ncut algorithm solution has a form of generalized eigenvalues problem (I am not going to work through the problem statement in this post again, please, refer to the Ncut part of my previous post):
Here is a degree matrix, is an adjacency matrix and is a vector, where positive items correspond to one cluster and negative items - to the other, is a ratio of sizes between the part of graph, we want to select, and the remaining part of the graph. The value, we aim to minimize in the first equation, is called Rayleigh quotient.
This minimization problem results in a generalized eigenvalue problem:
Here we aim to fins the smallest non-trivial eigenvalue produces the minimum of Rayleigh quotient.
matrix is also called Laplacian matrix and is called nomralized Laplacian matrix, because though this normalization generalized eigenvalue problem can be reduced to the regular eigenvalue problem. Indeed, make a variable substitution:
The normalized Laplacian matrix is stochastic, hence, the smallest in absolute value eigenvalue is and eigenvector . We aim to find the second smallest eigenvalue.
Interestingly, the constraint can be lifted, because every solution satisfies it. Indeed, the eigenvector with smallest eigenvalue is . Then every other eigenvector is orthogonal to it, because the Laplacian (D - S) is symmetric, making normalized Laplacian symmetric, too. Then all of their eigenvectors are orthogonal to each other and
Now, in practice we also relax the second constraint and solve the system in real numbers, and if i-th coordinate takes a positive value, assume it 1, and if negative, assume that it takes the value of .
Connection between Ncut and ECI
Let us establish correspondence between the ECI equation and Ncut equation. Start with Ncut:
Multiply both sides by and split the terms and in the Laplacian :
Hence, we’ve established the correspondence between Ncut and ECI.
Practical example
Download a world exports dataset from the WTO website: https://stats.wto.org/. The groupings of products in this dataset are pretty crude, but still they should suffice for the purpose of understanding ECI.
Read in and clean the dataset:
wto_df = pd.read_excel('./data/WtoData_20221121023331.xlsx', skiprows=1, header=1)
# remove some columns with duplicates etc.
wto_df = wto_df[wto_df['Reporting Economy'] != 'European Union']
wto_df = wto_df[wto_df['Partner Economy'] == 'World']
wto_df = wto_df[wto_df['Reporting Economy'] != 'World']
Pivot the dataset:
pivoted_wto = wto_df.pivot(index='Reporting Economy', columns='Product/Sector', values='2020')
pivoted_wto = pivoted_wto.fillna(0).astype('int64')
pivoted_wto
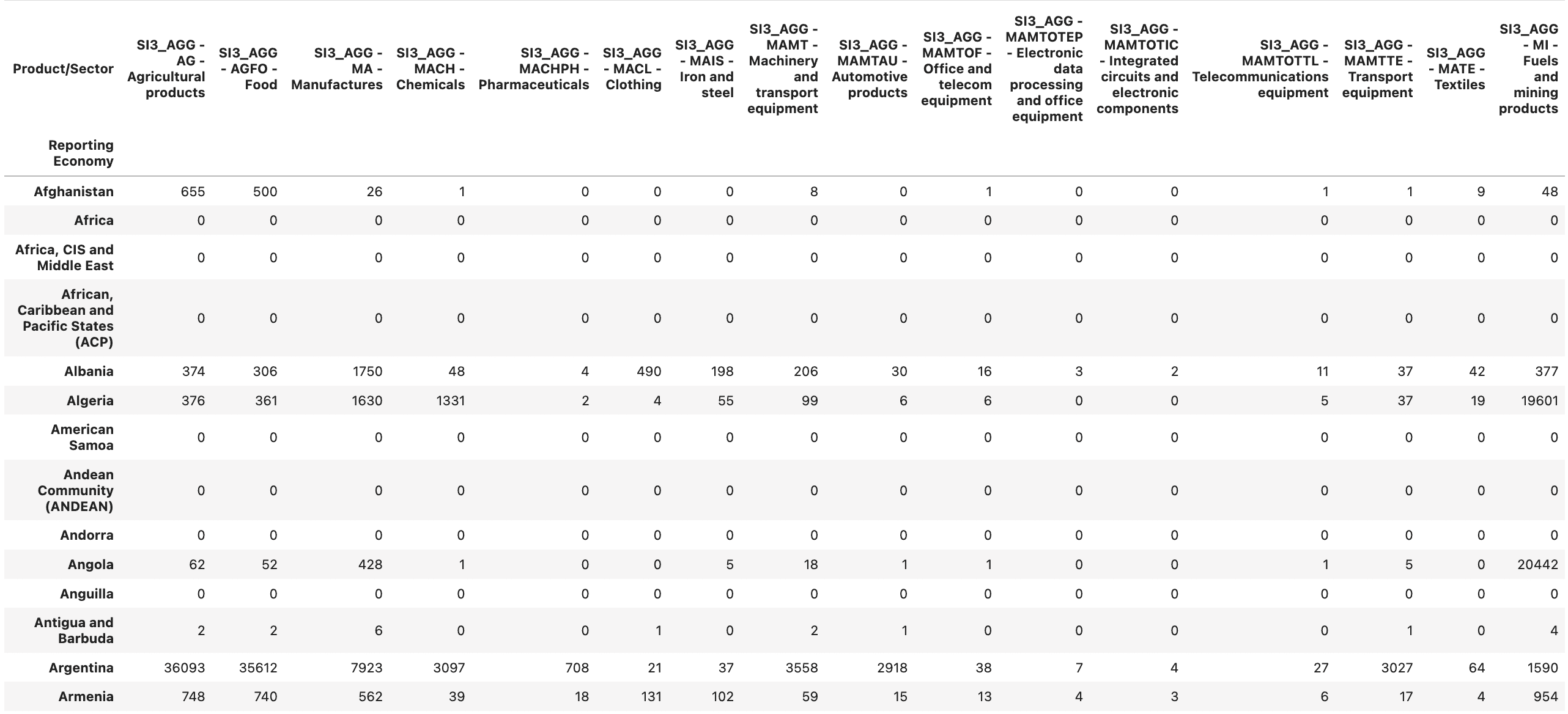
Calculate the RCA numerator and denominator for the future country-product matrix:
# calculate the rca_numerator
rca_numerator = pivoted_wto.div(pivoted_wto.sum(axis=1), axis=0)
# calculate the rca_denominator
rca_denominator = pivoted_wto.copy(deep=True)
product_sums = pivoted_wto.sum(axis=0)
for item in product_sums.index:
rca_denominator[item] = product_sums[item]
rca_denominator = rca_denominator.div(product_sums.sum(), axis=0)
rca_denominator
# calculate the country-product matrix (without the 0-1 discretization so far)
M = rca_numerator.div(rca_denominator)
M = M.fillna(0)
M

Let us look into the row of the country-product matrix, corresponding to China:
M.loc['China']

Now we get a hint on why China has a relatively low ECI for the first economy in the World: it lacks some commodities, such as food supplies and fuels as well as automotive parts (although it is now the single mightiest producer of automobiles in the World, manufacturing 26 million units a year, it is consuming most of them itself; however this situation is quickly changing, as Chinese automotive industry rapidly expands to the Russian and CIS markets in 2022).
We shall discretize the country-product matrix and sort its rows (countries) by :
discrete_M = M.applymap(lambda x: 1 if x >= 1 else 0)
sorted_discrete_M = discrete_M.loc[discrete_M.sum(1).sort_values(ascending=False).index]
sorted_discrete_M
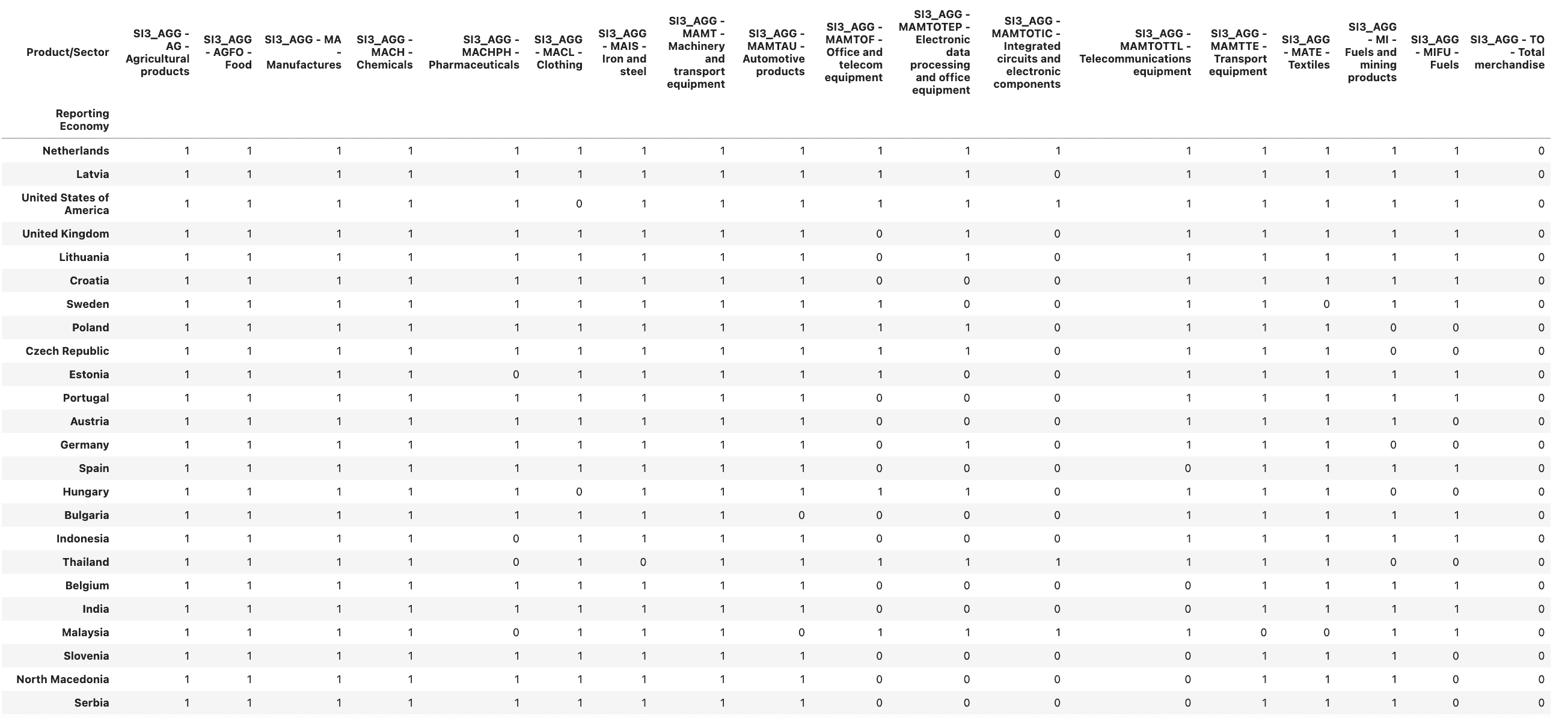
This is already starting to make sense: developed European coutries, such as Netherlands or Germany top the list, as well as the US and UK. China is in 40s, Russia is closer to the middle of the list.
If we were to draw the discretized country-product matrix, with rows sorted by , we get something like this:
from matplotlib import pyplot as plt
plt.matshow(sorted_discrete_M)

As you can see, the matrix indeed has a triangular nature.
At last, let us proceed with calculating the ECI as the second main eigenvector of normalized discretized country-product matrix:
# calculate economy complexities; some economies have 0 complexities, making matrix singular - regularize by adding a tiny number
economy_complexities = np.diag(sorted_discrete_M.sum(1).map(lambda x: 1/10 if x == 0 else x))
# get a diagonal C matrix
C = np.linalg.inv(economy_complexities)
# calculate product ubiquities
product_ubiquities = np.diag(sorted_discrete_M.sum(0))
# get a diagonal P matrix
P = np.linalg.inv(product_ubiquities)
# calculate the normalized discretized country-product matrix for ECI calculation
eci_matrix = C @ sorted_discrete_M.to_numpy() @ P @ sorted_discrete_M.to_numpy().T
# get eigenvalue and eigenvectors of the normalized discretized country-product matrix
values, vectors = np.linalg.eig(eci_matrix)
# get the second main eigenvector
vectors[:,1]

As you can see, we got our ECI vector, but most values in it are negative, and there is also a tail of positive/zero values, corresponding to countries, which were regularized by adding 1/10 etc.
Eigenvectors are defined up to a constant, so let us multiply all the coordinates by (-150) to get a more reasonable range of values:
vectors[:,1] * (-150)

Now we can see that most of our ECI vector coordinates took reasonable values, and the normalized variables took large negative or 0 values. Great!
References:
- https://en.wikipedia.org/wiki/Revealed_comparative_advantage - revealed competitive advantage/Balassa index
- https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0070726
- https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0047278
- https://arxiv.org/pdf/1711.08245.pdf - connections with normalized cut, diffusion map, kernel PCA etc.
- https://people.eecs.berkeley.edu/~malik/papers/SM-ncut.pdf - normalized cut
- https://people.eecs.berkeley.edu/~wainwrig/stat241b/scholkopf_kernel.pdf - Scholkopf on kernel PCA
- https://web.cse.ohio-state.edu/~belkin.8/papers/LEM_NC_03.pdf - original paper on spectral embedding/Laplacian eigenmaps
- https://stats.stackexchange.com/questions/463141/what-is-the-difference-between-spectral-clustering-and-laplacian-eigenmaps - on correspondence of spectral clustering and LLE

Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram