

Amazon Alexa
February 07, 2019 4 min read
Послушал двух парней из кембриджского офиса Амазона, работающих над Алексой. Составил общее впечатление о том, каково оно - работать в Амазон.
Про жизнь и про людей
Докладчикам, я бы сказал, было около 42 и 36 лет соответственно. Тот что постарше - Roberto Barra-Chicote - профессор из Мадрида, поговорили, внезапно, с его женой (мы раньше пришли, и я случайно с ней разговорился). Жена работает в Accenture, сейчас они наконец родили детей, и она в отпуске. В консалтинге ее упахивали, конец рабочего дня формально в 7, так что в среднем хорошо если добиралась домой к 8:30, но раньше начальника уходить не принято, а тот запросто сидел и до 11. Она делала по 13 проектов параллельно.

Среди top tech-компаний Амазон вообще-то тоже всегда славился плохим обращение с сотрудниками, но в Кембриджском офисе вроде бы помягче - английская культура сказывается. Жена говорит, что Роберто почти всегда приходит домой строго в 5:30.
В кембирджском университете есть несколько очень сильных профессоров, специализирующихся в речевых технологиях, вроде специалистов в переводе Билла Бирне или в распознавании речи Марка Гейлса. Поэтому логично, что здесь же располагается ряд комманд, отвечающих за Алексу.
А Амазона есть 2 pizzas rule - в каждой команде должно быть не больше людей, чем можно накормить двумя пиццами. Как правило, 6-8. Примерно пополам инженеров и ученых, выполняющих взаимодополняющие функции. Проекты обычно небольшие по длительности, около полугода-года, что по меркам менеджеров медленно, а по меркам ученых - быстро.
Всего над Алексой в разных офисах работает около 9 тысяч (!) человек. По моим прикидкам даже в AWS задействовано всего тысяч 20 программистов. Так что проект просто гигантский, и Амазон на него, видимо, поставил очень много. Подтягивается и сообщество: со старта "Алексы" в 2014 сторонние разработчики успели написать уже 80,000 скиллов.
Помимо Алексы в кембриджском офисе находится еще несколько команд: Prime Air (дроны-доставщики), Lab 126, AWS S3 и Shield.
Роберто - спец по text2speech. Доклад у него был превосходный, чувствуется опыт преподавания, ничего лишнего он не проболтнул, зато ликбез провел очень структурированный и познавательный.

Другой докладчик - Christos Christodoulopoulos - помоложе и рассказывал похуже. Он спец по knowledge representation - его стараниями Алекса умеет выкапывать информацию из интернета и дает какие-то внятные ответы на вопросы. Рассказывал про свою последнюю статью - как они заставили аннотаторов из отделения в Бостоне собрать датасет с 180,000 фактов + статьями, подтверждающими эти факты.
Про технологии (возможно, скучновато)
Насколько я понял, основная часть продакшн-стека у Амазона - на Яве и Спарке.
Алекса состоит из доброго десятка подсистем. Каждая подсистема имеет свое API, которое висит где-то в Амазоновском облаке и к которому обращается колонка, когда нужно выполнить какую-то задачу. По-видимому, за разработку каждой подсистемы отвечает отдельная команда или группа команд.
- Человек произносит фразу (Utterance)
- Модуль Автоматического Распознавания Речи (Automatic Speech Recognition, ASR) генерирует текст фразы
- Модуль Распознавания Естественного Языка (Natural Language Understanding, NLU) распознает суть запроса
- С помощью Скиллов (Skills) Алекса выполняет запрос и возвращает текст
- Модуль Преобразования Текста в Речь (Text to speech, TTS) читает текст ответа

Text to speech
Roberto Barra-Chicote
Модуль Text to Speech до эры нейронок работал так: из текста делалась фонетическая транскрипция, а по той затем статистическими моделями/Витерби генерировалась речь. Вокодер (модуль, генерирующий речь) на марковских цепях работал сравнительно плохо.
Сейчас этот пайплайн заменили на нейронки.


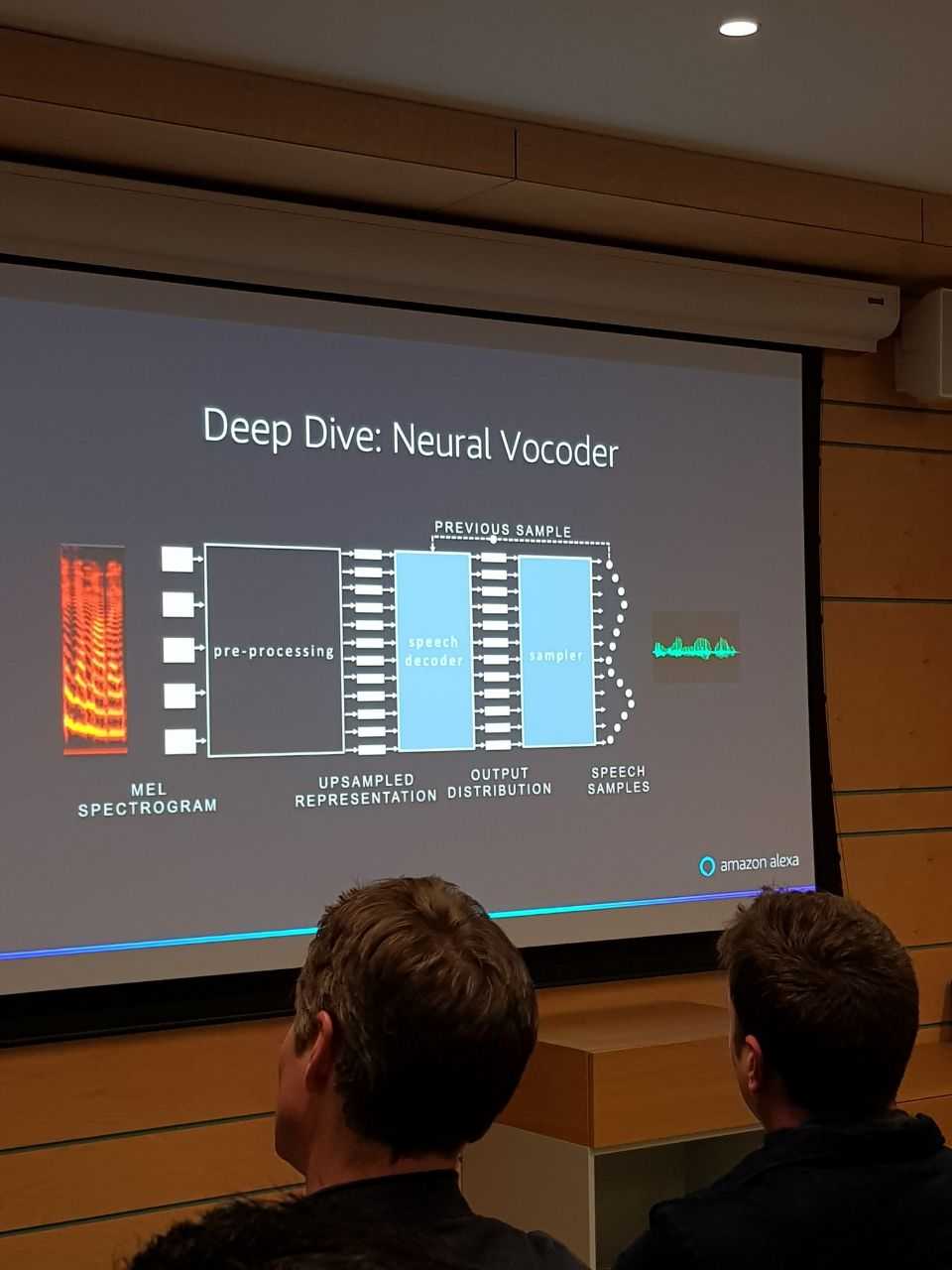
Отдельная проблема - оценивать качество синтезированной речи. Для этой цели есть MUSHRA test.
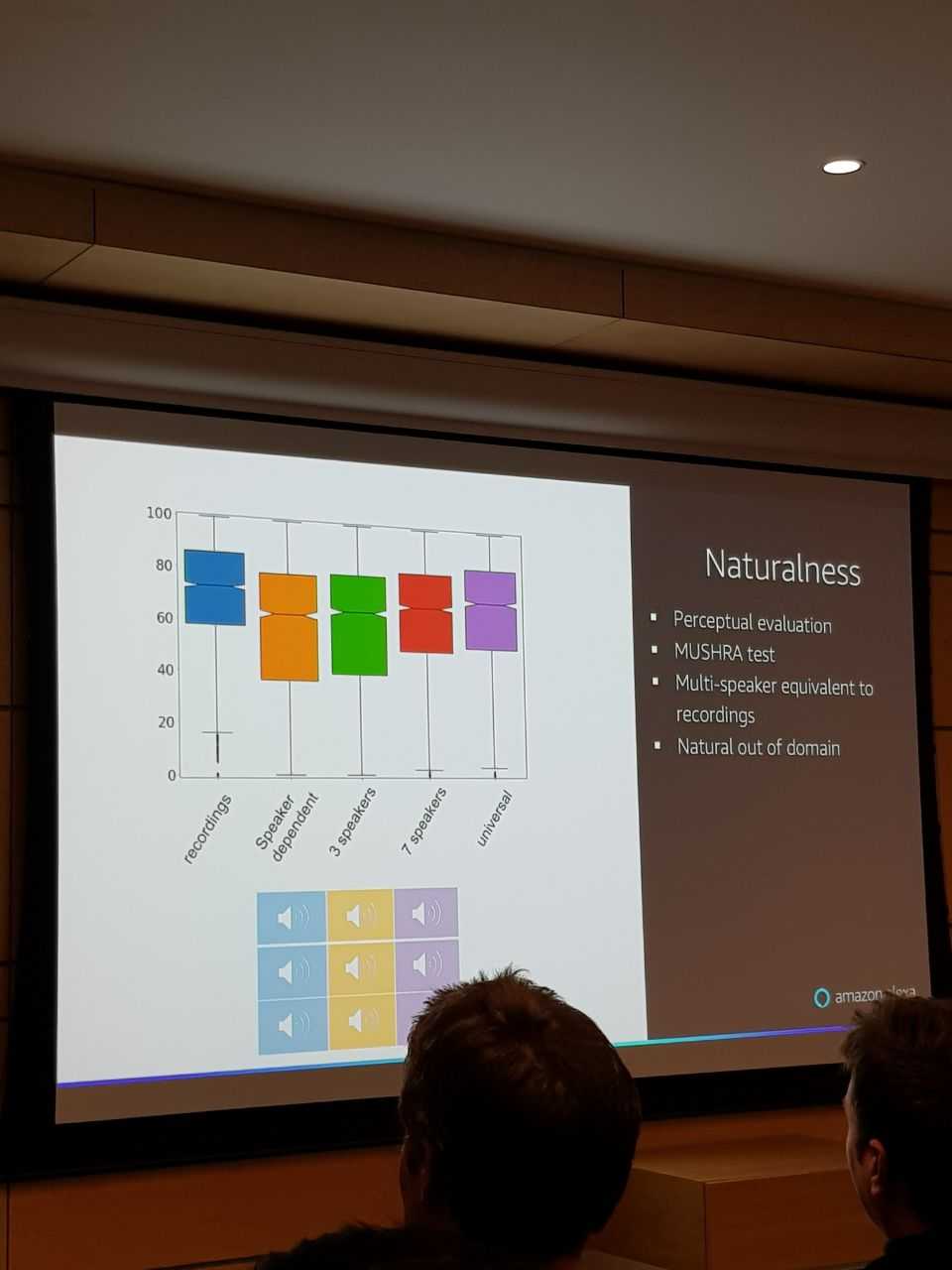
Для тренировки Амазоновского нейронного вокодера используется датасет AWS voices portfolio с более чем 200 часами аудио.
Knowledge Representation
Christos Christodoloupoulos
В базе знаний Алексы хранятся именованные сущности и именованные отношения между ними:

Проблемы в работе с базой знаний:
- хранение/запросы
- целостность: ingestion checks, устаревшие факты
- запросы: эффективный обход графа, сгенерированные факты
Проблемы исследований
- полнота: веса фактов должны задаваться с учетом спроса на них со стороны данного приложения
- экстракция: структурированные и неструктурированные источники, унификация онтологий, источники на множестве языков
- верификация: оценка корректрости фактов, поиск подтверждений
Зачем автоматизировать верификацию? Чаще обновления (чтобы успевать за скоростью/масштабом данных экстракции), пополнение базы проверенных фактов, расширение списка источников, возможность выдавать подтверждения фактов.
Христос рассказывал про их последнюю статью: они с интерном и толпой аннотаторов в Бостоне собрали огромный датасет из 185,000 истинных и ложных утверждений, притом каждое утверждение было снабжено фактическими подтверждениями, из которых следовало, что утверждение поддерждается/опровергается/недостаточно данных.
FEVER: a Large-scale dataset for Fact Extraction and VERification
Thorne et al. (2018), fever.ai
Утверждения набрали из дампа 5.4 миллионов страниц английской википедии за июнь 2017, взяли 50,000 самых популярных статей, взяли только введения из статей, нарезали на предложения, с помощью CoreNLP выделили токены. Для генерации фактов использовались только простые предложения с одним фактом на предложение.
Затем к фактам применяли мутации:
- пересказ иными словами
- отрицание
- обобщение
- уточнение
- замена сходными сущностями/отношениями (например, Америка -> Канада)
- замена несходными сущностями/отношениями (например, Америка -> крокодил)
Про измененные факты говорили, верны они или нет. Просили анноторов про каждое утверждение найти гиперссылку в интернете. Например, если дан факт "Брэд Питт - актер", надо было найти веб-страницу про фильм, где он играет. Получили precision 95.4%, recall 72.4%. Ошибки происходили часто оттого, что трудно было избавиться от априорных знаний о мире, вносимых аннотаторами. То есть, к примеру, в ряде ситуаций факт что "Огайо находится в США" должен был классифицироваться как "недостаточно данных", но бостонские аннотаторы писали что "верно".
После этого они устроили FEVER challenge - и предложили произвольным командам извлечь дополнительные аннотации лучше, чем делали они сами. Получилось, 23 команды из разных университетов нашли 1200 дополнительных аннотаций и превзошли самих ребят из Амазона на 37%:
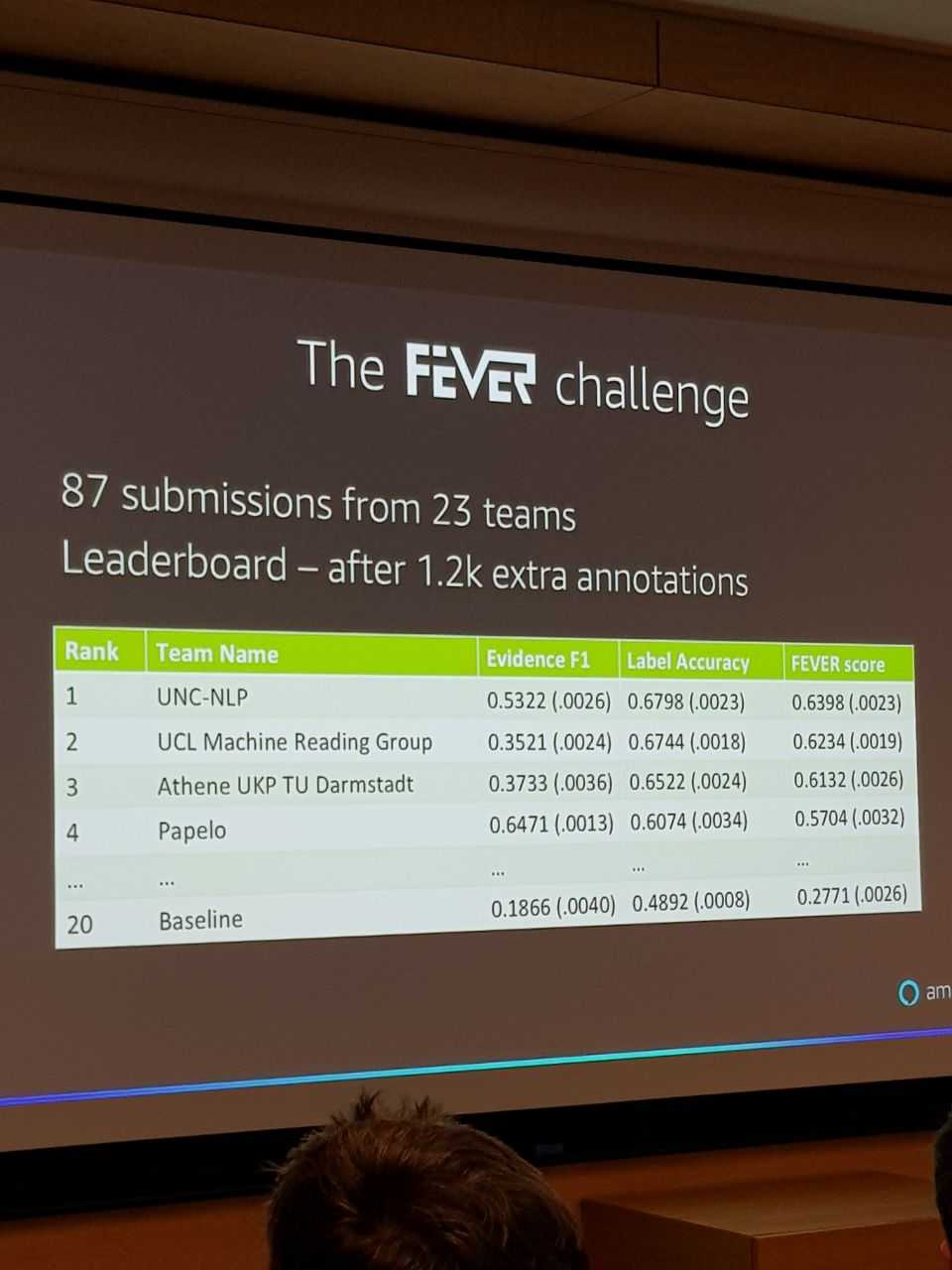
В итоге по итогам всей этой работы точность ответов Алексы должна была сильно возрасти.
Мораль
По моим впечатлениям от докладов Амазона и DeepMind, современные ИИ-продукты состоят из нескольких АПИ, каждое из которых делается отдельной командой от 6 человек и повторно используется в разных продуктах. Ведет каждую такую команду специалист в соответствующем поле с большим стажем, а на подхвате у него - куча ученых помоложе и классных инженеров. Неплохо иметь какое-то представлене о каждой из этих научных областей, чтобы представлять, что достижимо, а что нет, но в целом бизнес, по-видимому, решает все-таки гораздо больше, чем отдельные команды технарей.

Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram