Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past.
Here I discuss, how to derive F distribution as a random variable, which is a ratio of two independent chi-square disributions. I'll also briefly discuss F-test and ANOVA here.
In my previous posts I’ve described Chi-square distribution (as a special case of Gamma distribution) and Pearson’s Chi-square test, from which many other distributions and tests are derived in the field of statistics.
In this post I am going to derive the distribution function of a Snedecor’s F distribution. It is essentially a ratio between two independent Chi-square-distributed variables with n and m degrees of freedom respectively ξ=χm2χn2.
In order to infer its probability density function/cumulative distribution function from the ratio, I’ll have to discuss non-trivial technicalities about measure theory etc. first.
Conditional probabilities of multi-dimensional continuous variables
Suppose that we need to calculate the probability density function of a random variable ξ, which is a multiple of 2 independent random variables, η and ψ.
First, let us recall the definition of independent random variables in a continuous case: fη,ψ(x,y)=fη(x)⋅fψ(y). Basically, joint probability density function is a multiplication of individual probability density functions.
Thus, cumulative distribution function Fη,ψ(x,y)=t=−∞∫xs=−∞∫yfη(t)fψ(s)dtds.
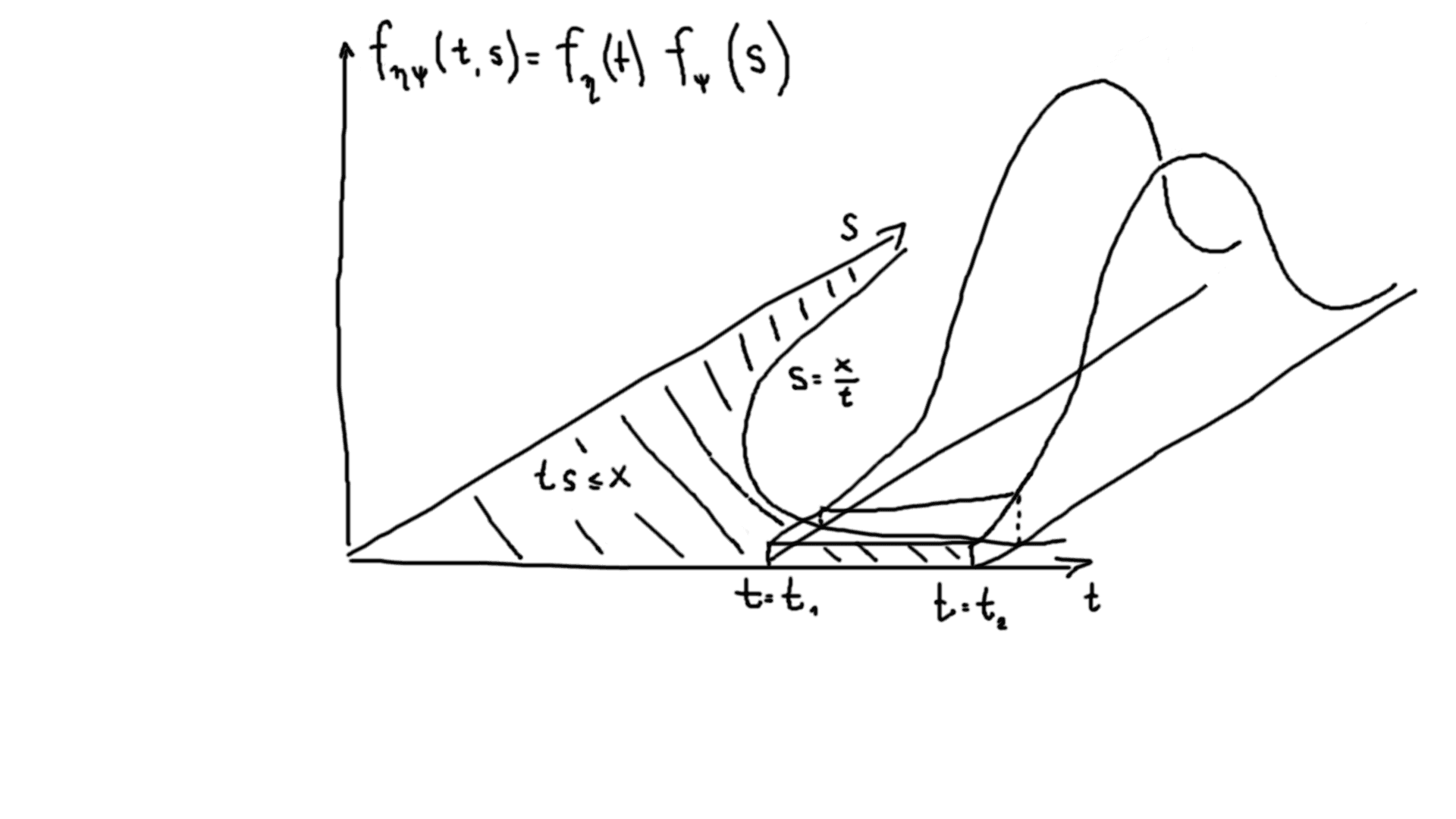
Now, we need to calculate the cumulative distribution function of a multiple of 2 random variables. The logic is similar to convolutions in case of a sum of variables: if the product ηψ=x, we allow η to take an arbitrary value of t, and ψ should take value of tx then.
We will be integrating fη(t)fψ(s) in a space, where s=tx, we have to multiply the integrand by Jacobian determinant ∣∣dxds∣∣=t1.
Thus, probability density function of F distribution is fχm2χn2(x)=t=0∫∞fχn2(t)fχm21(tx)t1dt.
Similarly, cumulative distribution function Fηψ(x)=t=0∫∞s=0∫x/tfη(t)fψ(s)dtds=t=0∫∞Fψ(tx)fη(t)dt=t=0∫∞p(ψ≤tx)dFη(t)=t=0∫∞p(ψ≤tx)p(t≤η<t+dt) (note that multiplication of integrand by Jacobian is not required here, as this is a proper 2D integral).
Graphically, it represents the integral of 2-dimensional probability density function over the area, delimited by s=tx curve:
Off-topic consistency considerations
Please, skip this section, it is a memento for myself, the product of my attempts to reason about how this integration works.
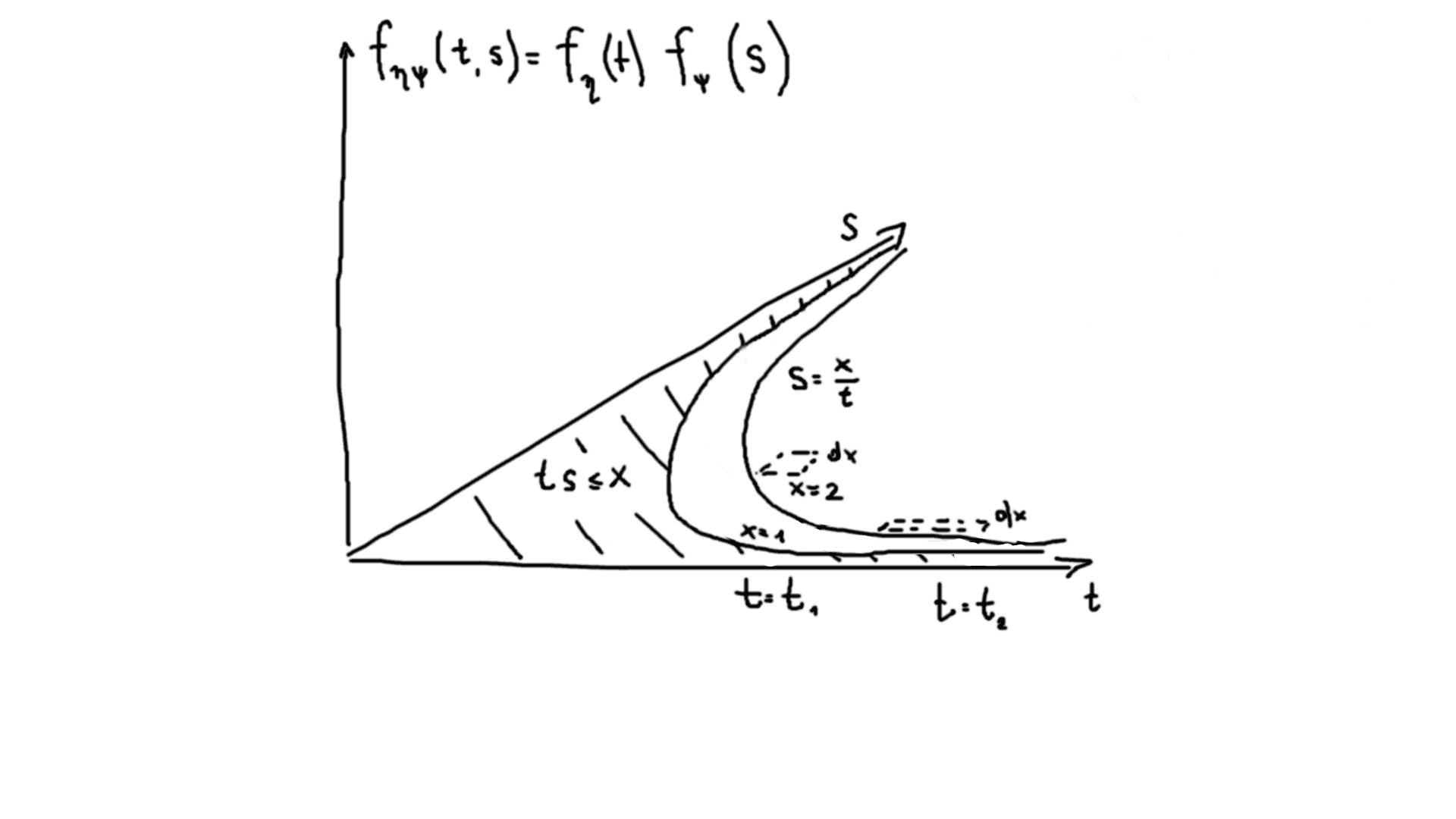
Suppose, we want to get c.d.f. from p.d.f.: Fηψ(x)=x=−∞∫+∞fηψ(x)dx. How to interpret it? x=ts is an area, so dx is a unit rectangle; fηψ(x) is an integral of fψ(s)fη(t) over the length of each hyperbola, corresponding to a single x value. When we integrate over the length of each hyperbola, as we approach infinity with s, t approaches zero, so the area of x stays the same.
A consistency consideration: we can infer p.d.f. from inequalities directly and see that integration is consistent:
We want to calculate the probability density function of F distribution as a multiple of 2 distributions, chi-square and inverse chi-square. But we need to invert χm2 first to do so. We’ll have to derive the probability density function of inverse chi-square distribution.
Inverse chi-square distribution
Recall the probability density function of chi-square distribution: fχn2=22nΓ(n/2)x2n−1e−x/2.
Substituting it into the expression for p.d.f., we get: fχm2χn2(x)=Γ(n/2)Γ(m/2)Γ(2n+m)22m+n22n+m(x+1x)2n+mx2m+11=Γ(n/2)Γ(m/2)Γ(2n+m)(x+1)2n+mx2n−1.
Normalization of chi-square distributions by degrees of freedom
In actual F distribution chi-squared distributions are normalized by their respective degrees of freedom, so that F=mχm2nχn2
The general form of F distribution probability density fmχm2nχn2(x)=mnΓ(2m)Γ(2n)(mnx+1)(m+n)/2Γ(2m+n)(mnx)n/2−1=Γ(2m)Γ(2n)(mnx+1)(m+n)/2Γ(2m+n)(mn)n/2xn/2−1.
F distribution is a special case of Beta-distribution
It is easy to notice that the expression Γ(2m)Γ(2n)Γ(2m+n) is inverse of Beta-functionB(x,y)=Γ(x+y)Γ(x)Γ(y).
It is also easy to see that (x+1)2n+mx2n−1 is a typical integrand of an incomplete Beta-function, as the one used in Beta-distribution probability density function.
Thus, F distribution is just a special case of Beta-distribution f(x,α,β)=B(α,β)xα−1(1−x)β−1=Γ(α)Γ(β)Γ(α+β)xα−1(1−x)β−1.
F-test
F-test is just an application of F distribution to data.
Suppose you have a set of patients, and some subset of them receives a treatment. You need to prove that the treatment works.
You measure some parameter (e.g. duration of sickness) for the treated patients and for the whole set of patients.
You then assume a null-hypothesis that there is no difference between treated patients. If the null-hypothesis holds, the ratio of sample
variances between treated patients and all patients should be F-distributed. If the p-value obtained in this test is too
small, you reject the null hypothesis and claim that the treatment works.
Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram