
R2 metric for regression

In this post I derive the coefficifent of determination (R2) metric for regression, explain its interpretations, connection to explained variance etc.
Optimizers in deep learning

In this post I briefly describe the concepts beside the most popular optimizer algorithms in deep learning. I cover SGD, RMSprop, AdaGrad, Adam, AdamW, AMSGrad etc.
Gradient boosting machines 101

Gradient boosting machines have been the most efficient method for working with tabular data for the last 10 years. In this post I am going to discuss flavours of GBMs, which originated in these years, their quirks and use cases.
Conjugate gradients

Conjugate gradients is one of the most popular computationally effective methods, used to solve systems of linear equations. Along with other Krylov space methods it can also be used for finding eigenvalues and eigenvectors of a matrix.
Intro to the Extreme Value Theory and Extreme Value Distribution

Quite often in mathematical statistics I run into Extreme Value Distribution - an analogue of Central Limit Theorem, which describes the distribution of maximum/minimum, observed in a series of i.i.d random variable tosses. This is an introductory text with the basic concepts and proofs of results from extreme value theory, such as Generalized Extreme Value and Pareto distributions, Fisher-Tippett-Gnedenko theorem, von Mises conditions, Pickands-Balkema-de Haan theorem and their applications.
Variational Autoencoder (VAE)

Here I discuss one of the two most popular classes of generative models for creating images.
MDS, Isomap, LLE, Spectral embedding

In this post I investigate the multi-dimensional scaling algorithm and its manifold structure-aware flavours.
Economic Complexity Index (ECI)

The death of globalism in 2022 brings all kinds of economic sanctions. Lately I've been running into the term Economic Complexity Index (ECI), which reflects the diversification of exports of a country. In this post I investigate the mathematics behind it and draw connections to the problems of Ncut, biclustering etc.
Correspondence between symmetric NMF, k-means, biclustering and spectral clustering

Non-negative matrix factorization (NMF) is the most fashionable method of matrix decomposition among productive, but mathematically illiterate biology students, much more popular than PCA due to its perceived simplicity. However, if you start digging deeper, it happens to have profound connections to a multitude of other techniques from linear algebra and matrix analysis. In this post I discuss those connections.
Intro to compressed sensing

For almost a century the field of signal processing existed in the paradigm of Nyquist-Shannon theorem (also known as Kotelnikov theorem in Russian literature) that claimed that you cannot extract more than n Fourier harmonics from a signal, if you have n measurements. However, thanks to the results in functional analysis from 1980s, such as Lindenstrauss-Johnson lemma and Kashin-Garnaev-Gluskin inequality, it became evident, that you can do with as few as log(n)! After application of the L1-norm machinery developed in 1990s, such as LASSO and LARS, a new groundbreaking theory of compressed sensing emerged in mid-2000s to early 2010s. In this post I'll briefly cover some of its ideas and results.
Lagrange multipliers and duality

Lagrange multipliers are ubiquitous in optimization theory and natural sciences, such as mechanics and statistical physics. Here I work out its intuition and derivation.
Lasso regression implementation analysis

Lasso regression algorithm implementation is not as trivial as it might seem. In this post I investigate the exact algorithm, implemented in Scikit-learn, as well as its later improvements.
Modern Portfolio Theory... and Practice

Throughout the 2020-21 pandemics the M2 money supply of the majority of European currencies exploded by 20-25%, of US dollar - by whopping 40%! Interest rates on investment-grade bonds are negligible compared to that, and they no longer serve their purpose as the primary conservative investment (3% interest is not any good, if the body of the bond looses 10-20% of its value a year because of the excessive money creation). Thus, a conservative investor has to go for a diversified portfolio of stocks, which can be constructed in the framework of the Modern Portfolio Theory - a trivial application of linear algebra and numeric optimization (oh, I meant, artificial intelligence, what am I saying). And as they say in Russia, the difference between theory and practice is that in theory there is no difference, while in practice there is some.
How does DeepMind AlphaFold2 work?
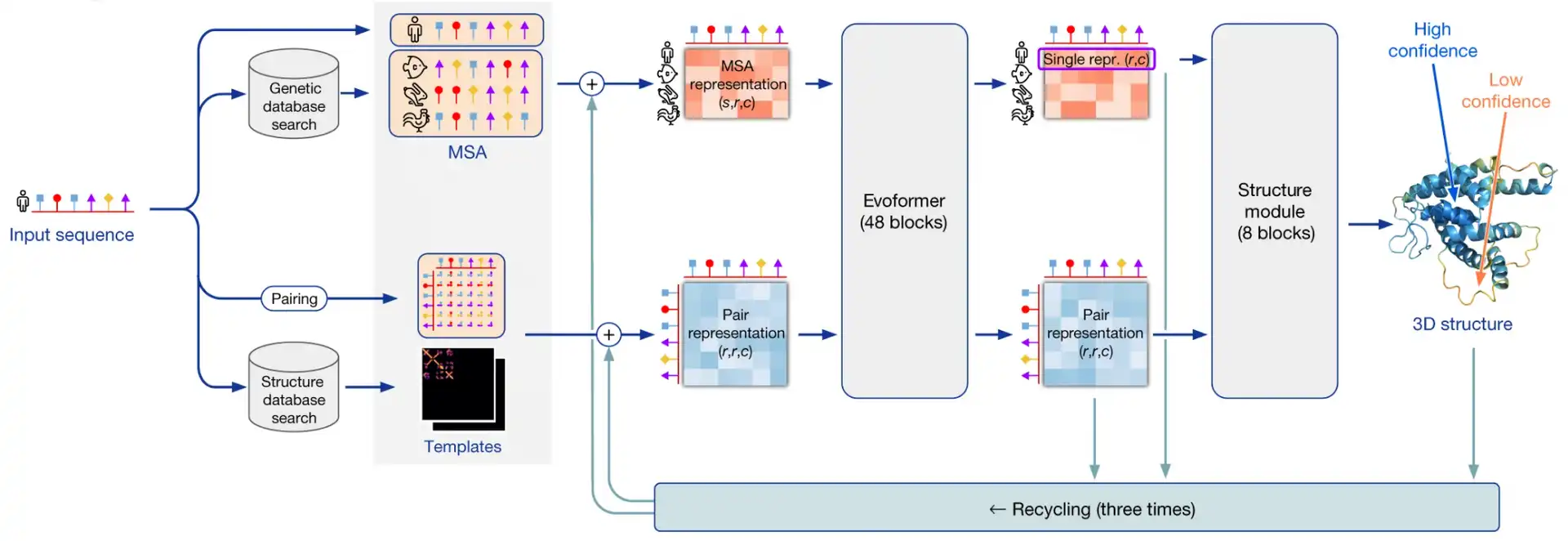
I believe that DeepMind AlphaFold2 and Github Co-pilot were among the most prolific advances of technology made in 2021. Two years after their initial breakthrough, DeepMind released the second version of their revolutionary system for protein 3D structure prediction. This time they basically solved the 3D structure prediction problem that held for more than 50 years. These are the notes from my detailed talk on the DeepMind AlphaFold2 system.
Quadratic programming

Solution of quadratic programming problem in polynomial time by Soviet mathematicians in the late 1970s - early 1980s paved the way for several important machine learning methods of 1990s, such as Lasso/ElasticNet regression (with its L1 regularization) and Support Vector Machines (SVM). These methods are incredibly useful, because they produce sparse solutions, effectively serving as a proxy for L0 regularization, in feature space/data point space respectively. Thanks to QP magic, they manage to do this in polynomial time, while straightforward application of L0 norm is NP-hard and cannot be done efficiently.
Overview of consensus algorithms in distributed systems - Paxos, Zab, Raft, PBFT

The field of consensus in distributed systems emerged in late 1970s - early 1980s. Understanding of consensus algorithms is required for working with fault-tolerant systems, such as blockchain, various cloud and container environments, distributed file systems and message queues. To me it feels like consensus algorithms is a rather pseudo-scientific and needlessly overcomplicated area of computer science research. There is definitely more fuzz about consensus algorithms than there should be, and many explanations are really lacking the motivation part. In this post I will consider some of the most popular consensus algorithms in the 2020s.
Divergence, Gauss-Ostrogradsky theorem and Laplacian

Laplacian is an interesting object that initially was invented in multivariate calculus and field theory, but its generalizations arise in multiple areas of applied mathematics, from computer vision to spectral graph theory and from differential geometry to homologies. In this post I am going to explain the intuition behind Laplacian, which requires the introduction of the notion of divergence first. I'll also touch the famous Gauss-Ostrogradsky theorem.
Johnson-Lindenstrauss lemma

Johnson-Lindenstrauss lemma is a super-important result on the intersection of fields of functional analysis and mathematical statistics. When you project a dataset from multidimensional space to a lower-dimensional one, it allows you to estimate, by how much you distort the distances upon projection. In this post I work out its proof and discuss applications.
Intro to spectral graph theory

Spectral graph theory is an amazing connection between linear algebra and graph theory, which takes inspiration from multivariate calculus and Riemannian geometry. In particular, it finds applications in machine learning for data clustering and in bioinformatics for finding connected components in graphs, e.g. protein domains.
Singular Value Decomposition

Singular value decomposition is a way of understanding a rectangular (i.e. not necessarily square) matrix from the operator norm standpoint. It is complementary perspective to eigenvalue decomposition that finds numerous application in statistics, machine learning, bioinformatics, quantum computers etc. This post explains its nature and connections to operator norm, least squares fitting, PCA, condition numbers, regularization problems etc.
Condition numbers

The notion of condition numbers arises when you are studying the problem of numeric stability of solutions of ordinary linear equations systems (OLES). This concept is really important in such practical applications as least-squares fitting in regression problems or search of inverse matrix (which can be an inverse of covariance matrix in such machine learning applications as Gaussian processes). Another example of their use is the time complexity of quantum algorithms for solving OLES - complexity of those algorithms is usually a polynomial or (poly-) logarithmic function of condition numbers. This post gives a brief review of condition numbers.
Normal matrices - unitary/orthogonal vs hermitian/symmetric

Both orthogonal and symmetric matrices have orthogonal eigenvectors matrices. If we look at orthogonal matrices from the standpoint of outer products, as they often do in quantum mechanics, it is not immediately obvious, why they are not symmetric. The demon is in complex numbers - for symmetric matrices eigenvalues are real, for orthogonal they are complex.
Kernel methods and Reproducing Kernel Hilbert Space (RKHS)

Kernel methods are yet another approach to automatic feature selection/engineering in the machine learning engineer's toolbox. It is based on theoretical results from the field of functional analysis, dating to 1900s and 1950s, called Reproducing Kernel Hilbert Space. Kernel methods, such as kernel SVMs, kernel ridge regressions, gaussian processes, kernel PCA or kernel spectral clustering are very popular in machine learning. In this post I'll try to summarize my readings about this topic, linearizing the pre-requisites into a coherent story.
Roadmap to understanding the quantum mechanics
In my university days I used to attend a course of quantum chemistry/mechanics, which was given in a typical post-soviet education style. All formalism, no essentials. As quantum computers are getting closer and closer to the reality by the day, I had a practical reason to finally improve my understanding of the theory. Here is my roadmap to understanding the quantum mechanics.
Wishart, matrix Gamma, Hotelling T-squared, Wilks' Lambda distributions

In this post I'll briefly cover the multivariate analogues of gamma-distribution-related univariate statistical distributions.
Principal components analysis

Principal components analysis is a ubiquitous method of dimensionality reduction, used in various fields from finance to genomics. In this post I'm going to consider PCA from different standpoints, resulting in various perspectives on it.
Beta distribution and Dirichlet distribution

Beta distribution and Dirichlet distribution are Bayesian conjugate priors to Bernoulli/binomial and categorical/multinomial distributions respectively. They are closely related to gamma-function and Gamma-distribution, so I decided to cover them next to other gamma-related distributions.
Multivariate normal distribution

Multivariate normal distribution arises in many aspects of mathematical statistics and machine learning. For instance, Cochran's theorem in statistics, PCA and Gaussian processes in ML heavily rely on its properties. Thus, I'll discuss it here in detail.
Cochran's theorem

Here I discuss the Cochran's theorem that is used to prove independence of quadratic forms of random variables, such as sample variance and sample mean.
Student's t-distribution, t-test

Here I discuss, how to derive Student's t-distribution, an important statistical distribution, used as a basis for t-test.
Snedecor's F distribution and F-test

Here I discuss, how to derive F distribution as a random variable, which is a ratio of two independent chi-square disributions. I'll also briefly discuss F-test and ANOVA here.
Pearson's Chi-square test - intuition and derivation

Here I discuss, how an average mathematically inclined person like myself could stumble upon Karl Pearson's chi-squared test (it doesn't seem intuitive at all from the first glance). I demonstrate the intuition behind it and then prove its applicability to multinomial distribution.
Survival analysis - survival function, hazard rate, cumulative hazard rate, hazard ratio, Cox model

Here I discuss the statistics apparatus, used in survival analysis and durability modelling.
Data structures for efficient NGS read mapping - suffix tree, suffix array, BWT, FM-index

In Next-Generation Sequencing bioinformatics there is a problem of mapping so-called reads - short sequences of ~100 nucleotides - onto a full string that contains them - the reference genome. There is a number of clever optimizations to this process, which I consider in this post.
Gamma, Erlang, Chi-square distributions... all the same beast

Probably the most important distribution in the whole field of mathematical statistics is Gamma distribution. Its special cases arise in various branches of mathematics under different names - e.g. Erlang or Chi-square (and Weibull distribution is also strongly related) - but essentially are the same family of distribution, and this post is supposed to provide some intuition about them.
DeepMind - Презентация AlphaFold в EBI

Два месяца назад весь мир облетела новость, что DeepMind выиграл известное соревнование по предсказанию 3D-структур белков CASP, порвав всех биоинформатиков с впечатляющим отрывом. Многие люди из мира биотеха теперь пытаются осознать, 'что это было'? Революция или эволюция, наука или инженерия, талант или финансирование? Волею судеб я когда-то оказался совсем недалеко от этой области науки, поэтому потратил несколько дней чтобы разобраться в деталях - а между тем в EBI приехал наводить мосты ведущий инженер проекта Эндрю Сеньор из DeepMind.
Amazon Alexa

Послушал двух парней из кембриджского офиса Амазона, работающих над Алексой. Составил общее впечатление о том, каково оно - работать в Амазон.
Prowler.io

Побывал на презентации Prowler.io - самого модного кембриджского стартапа.
Встреча с Обри де Греем

Поглядел наконец живьем на главного геронтологического оптимиста.
Энигма, часть 5 - "Бисмарк" и "дебютантка"

В ходе "Битвы за Атлантику" в 41-ом году немецкий флот пытался отрезать Великобританию от морского сообщения с континентом и Штатами. У немцев было превосходство в военно-морском флоте, и на какое-то время им даже удалось установить вокруг островов морскую блокаду.
Энигма, часть 1 - Что такое "Энигма"?

Что вообще такое эта знаменитая "Энигма", которую все так стремились взломать, и зачем она была нужна?
Энигма, часть 0 - Британия во Второй мировой

Прежде чем перейти собственно к теме повествования, криптографии и Блетчли-парк, я хотел сказать пару слов об участии Британии в войне - чтобы дать контекст.
Энигма. Анонс

Все смотрели "Игру в Имитацию"? Камбербетч, конечно, прекрасен, а в жизни, конечно, всё было не так. Этот пост про математиков и инженеров из GC&CS (Government Code and Cypher School) во главе с Аланом Тьюрингом, нашедших уязвимости в немецких шифровальных машинах "Энигма" и "Лоренцå" во Вторую мировую войну, и спасших тем самым десятки или даже сотни тысяч соотечественников.