Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past.
Kernel matrix basically contains cosines of angles between vectors Xi and Xj (given their lengths are 1).
Now, in MDS we are seeking to approximate each p-dimensional data point Xi with a low-dimensional vector Yi, so that
the similarity matrix between Yi vectors approximates the kernel matrix K between Xi vectors.
Suppose, for instance, that Yi has a dimensionality of 2.
where Y1=(Y1,1,Y1,2) is a row vector of Y matrix.
What are the optimal column vectors ⎝⎛Y1,1Y2,1...Yn,1⎠⎞ of this matrix Y?
The answer is simple: those are eigenvectors/singular vectors of K (in this case it is the same, because K is a Gram matrix).
The best rank 2 approximation of K in terms of Frobenius norm is given by its partial SVD: K^=i=1∑2σiuiviT.
This can be shown by iteratively applying ∣∣K−σ1u1v1T∣∣F2=i=2∑nσi2 (e.g. see this SO post)
In this case K matrix is a Gram matrix, so its SVD is symmetrix K=UDVT=UDUT.
Now, how do we get from D matrix to K matrix? See the next section.
Kernelization and double centering
For now consider a matrix Xc=⎝⎛x1,1−n∑i=1nxi,1...xn,1−n∑i=1nxi,1x1,2−n∑i=1nxi,2...xn,2−n∑i=1nxi,2x1,p−n∑i=1nxi,p...xn,p−n∑i=1nxi,p⎠⎞, where we subtracted column means from each element, so that all the columns have zero sum.
Through SVD we can represent it as Xc=UDVT. And we can attain two Gram matrices out of it, left and right.
One of our Gram matrices would be a p-by-p covariance matrix, used in PCA:
Cc=XcTXc=VDUTUDVT=VD2VT
The other Gram matrix would be an n-by-n kernel matrix:
Kc=XcXcT=UDVTVDUT=UD2UT
Eigenvectors V of the covariance matrix Cc are right singular vectors of the matrix Xc and, incidentally, VD are Principal Components, obtained in PCA.
Eigenvectors U of the kernel matrix Kc are left singular vectors of the matrix Xc.
In a matrix notation how do we get Xc from X? Easy, we multiply it from the left by ⎝⎛1...00...0.........0...1⎠⎞−n1⎝⎛1...11...1.........1...1⎠⎞=I−n11n.
As a result, we get Xc=(I−n11n)X. Apply this to get centered kernel Kc from the raw kernel matrix K:
Hence, as we’ve just seen, double centering of distances matrix gives us the centered kernel matrix Kc.
For this matrix we can easily find an EVD/SVD and use it as a low-dimensional approximation of the matrix Kc (and,
hence, D(2)), providing us with the dimensionality reduction method.
Isomap and Locally Linear Embeddings (LLE)
It is easy to observe a limitation to the classical MDS algorithm: oftentimes data points form a so-called manifold in
the enveloping space. For instance, real-life 640x480 photos occupy only a small part of the space of all theoretically
possible 640x480 pixel signals. Moreover, this shape is continuous and smooth - you can transition from one real-life
photo to another one applying small changes.
Hence, the correct way to measure the distances between our data points is not euclidean distances in the enveloping
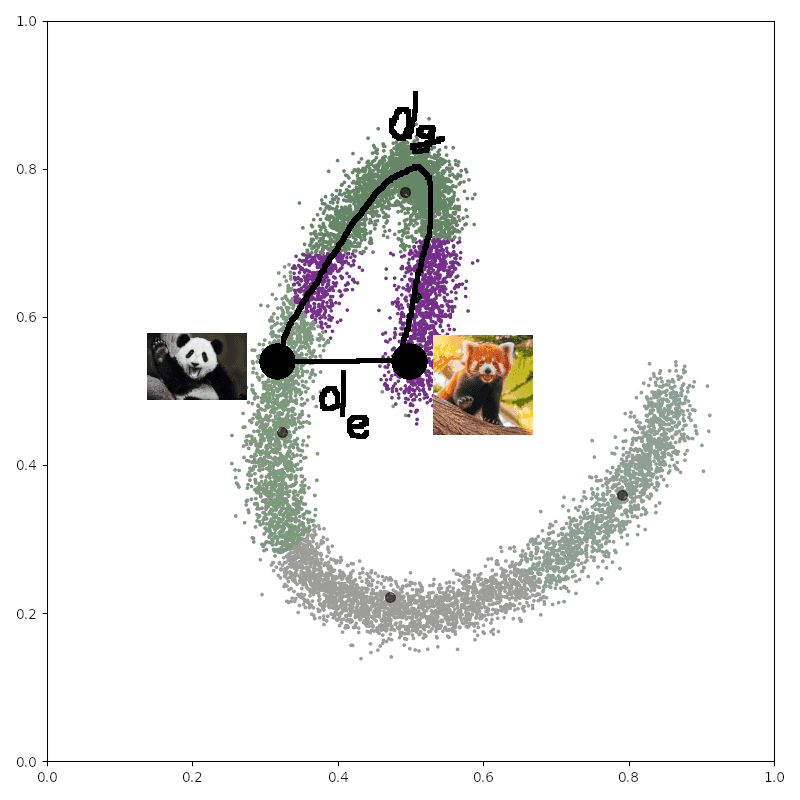
space, but geodesic on the manifold. For instance, if we compare photos of lesser panda and giant panda, they’d be close
in the enveloping space and euclidean distance de between them would be small, but they’d be far apart on the manifold,
because lesser panda is a racoon, and giant panda is a bear, so geodesic distance between them dg would be large.
Manifold of photos. Each data point corresponds to a photo. Photos of giant panda and
lesser panda are close in euclidean distance de, because they look similar, but far apart in geodesic distance dg,
because they actually belong to very different taxa.
In 2000 two manifold-aware methods were published in the same Science magazine issue.
Isomap
Isomap works in 3 simple steps:
Find k nearest neighbours of each point. Construct a weighted graph, connecting neighbouring points with edges, where weight of each edge is the Euclidean distance between those points.
Construct a distance matrix on that graph, using e.g. Dijkstra’s algorithm.
Using this distance matrix, perform MDS.
I don’t know what to add. The method is straightforward and self-explanatory, but beautiful.
Locally Linear Embeddings (LLE)
LLE is very similar to Isomap, but with a slightly different premise.
Find k nearest neighbours of each point. Construct a weighted graph, connecting neighbouring points with edges, where weight of each edge is the Euclidean distance between those points.
Construct a matrix W, such that each data point Xi is most accurately represented as a linear combindation of its neighbours with the weights from this matrix: Xˉi=j=1∑kWi,jXj, so that Φ(X)=i=1∑n∣Xi−j=1∑kWi,jXj∣2 is minimal (least square problem).
Using this matrix as a similarity matrix, find matrix Y of vectors Yi of low dimensionality, such that the following function is minimized: Φ(Y)=∣Yi−j=1∑kWi,jYj∣2.
The matrix W could be find with a simple least squares regression.
If you have a data matrix X and you’re looking for W, which best approximates XX^=W⋅X:
Essentially we have a linear regression problem for each row vector (X^1,1X^1,2X^1,3X^1,4), where each of
its coordinates can be perceived as y-s of a data point in regression problem, weights (W1,1,W1,2,W1,3) can be viewed
as regression weights and column-vectors ⎝⎛X1,1X2,1X3,1⎠⎞ can be viewed as
regression factors for current data point.
An alternative representation of our optimization problem is (Yi−j∑Wi,jYj)2=YT(I−W)T(I−W)Y. Again, this is a quadratic form,
which can be minimized by finding eigenvectors and eigenvalues of an extreme value decomposition of matrix
E=(I−W)T(I−W):
EY=ΛY,
where Λ is a diagonal matrix of eigenvalues and Y is the matrix of eigenvectors. We might need double centering
just as in MDS, which will lead us to a generalized EVD problem.
Spectral embedding through Laplacian Eigenmaps
Finally, let us consider Laplacian Eigenmaps algorithm as an implementation of spectral embedding.
It turns out that it draws connections to both LLE and normalized cut algorithm, considered in my previous post.
Again, the alogrithm consists of 3 steps, similar to those considered above:
Find k nearest neighbours (or, alternatively, ϵ-neighbourhood) of each data point.
Construct a weighted graph, so that the weights of each edge, connecting neighbouring vertices is a heat kernel: Wi,j=e−t∣∣xi−xj∣∣2. Alternatively just assign neighbour edges lengths 1 and non-neighbour - length 0 (which actually corresponds to t=∞).
Calculate the Laplacian matrix of this graph L=D−W (where D is as usual a diagonal matrix of degrees of vertices) and solve the normalized Laplacian equation for eigenvectors and eigenvalues:
Lf=λDf
Again, 0 eigenvalue corresponds to a trivial solution. Eigenvectors other than that are useful.
Justification of the algorithm
Representation as a trace of Laplacian
Suppose that you want to project the dataset onto a single line that preserves the squares of distances between points
as well as possible. This is very similar to a directional derivative: when you’re looking for a direction vector
d, which maximizes the derivative of a function f() in that direction, which means that ⟨d,∇f⟩.,
which means that the optimal d=∇f, because ⟨∇f,∇f⟩ is the maximum.
So, let us write this mathematically: we’re looking for a vector y=(y1,y2,...,yn)T maximizing ⟨W,Y(i−j)⟩,
where
In a more general case, if we’re looking for a low-dimensional (p-dimensional) approximation Y=⎝⎛y1,1y2,1...yn,1y1,2y2,2...yn,2............y1,py2,p...yn,p⎠⎞ of our distance matrix W, we come to:
argYTDYT=IminTr(YTLY)
Again, this result was shown in the section of one of my previous posts, dedicated to the Normalized Cut algorithm.
Laplace-Beltrami operator on a manifold guarantees optimality of mapping
Interestingly, here algebraic graph theory connects with differential geometry.
Recall that Laplacian of a graph bears this name for a reason: it is essentially the same Laplacian as in field theory (see my post on Laplacian in field theory) and this excellent post by Matthew Bernstein. In case of functions, defined on manifolds, it is also generalized by Laplace-Beltrami operator.
Suppose that our data points lie on a manifold. We shall be looking for a function f:M→R, mapping points of our manifold to a line (R1). This approach is somewhat similar to incrementally finding more and more directions that maximize explained variance in data in PCA.
In discrete graph case we were looking for vectors y, analogous to f, such that the
quantity i∑j∑Wi,j(yi−yj)2 was maximized. Recall that the optimized quantity was
alternatively represented as
i∑j∑Wi,j(yi−yj)2=yTLy=yTVT⋅Vy. Here
V is a discrete matrix, analogous to divergence (again, see Matthew Bernstein post), applied at each point of vector y of points.
In a continuous case the counterpart of this expression would be ∫M⟨∇f(x),∇f(x)⟩=∫M∣∣∇f(x)∣∣2. Here we replaced the discrete V matrix with a continuous gradient,
their dot product draws similarities to divergence and sum is replaced with integral over the manifold.
Please, refer to my previous posts on Normalized Cut and Economic Complexity Index, where
Normalized Cut algorithm is derived and explained. Conditions of Laplacian Eigenmaps are identical to
the conditions of Normalized Cut.
Connection to LLE
This one is instetsting.
E=(I−W)T(I−W)
Ef≈21L2f
Hence, eigenvectors of E coincide with the eigenvectors of Laplacian L. Let us prove this.
Step 1. Hessian approximation
(I−W)f≈−21j∑Wi,j(xi−xj)TH(xi−xj)
Let us use Taylor series approximation of our function f() at each of the neighbouring points xj near the point xi:
Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram