

Correspondence between symmetric NMF, k-means, biclustering and spectral clustering
August 31, 2022 38 min read
Non-negative matrix factorization (NMF) is the most fashionable method of matrix decomposition among productive, but mathematically illiterate biology students, much more popular than PCA due to its perceived simplicity. However, if you start digging deeper, it happens to have profound connections to a multitude of other techniques from linear algebra and matrix analysis. In this post I discuss those connections.
I am following the general logic of this paper, including the numeration of chapters, in this post. However, I will provide lots of my own remarks, as I spent several months, working with objects, discussed in this post and “rehydrate” this very clear, but somewhat condensed 4.5-page paper into a much larger blog post.
In this post I will present 4 seemingly different algorithms: symmetric NMF, k-means, biclustering and spectral clustering via normalized cuts method. I will establish the correspondence between all 4 methods and show that essentially they represent variations of the same mathematics.
1. Introduction to NMF and k-means
NMF and recommender systems
Consider an matrix .
Oftentimes you would want to approximate it by a low-rank matrix . E.g. suppose that “low-rank” means rank :
Here I use outer product notation to represent as a product of two rectangular matrices: matrix and matrix :
Since the Netflix challenge, this approach was very popular in the recommender systems. If matrix represents users, who assigned ratings to movies, then matrix represents the characterization of each of the users in terms of psychological traits (e.g. how much the user likes humour, violence, sentimentality etc.) and matrix characterizes each of movies in terms of these scales - how humorous, violent, sentimental etc. they are.
Then an obvious application of NMF is data imputation - most of the user reviews are missing, hence, we need to predict user ratings for movies they haven’t seen and suggest the movies with the highest expected ratings.
How would we search for NMF in practice? We would require Frobenius norm of the difference between NMF and the original matrix to be as small as possible:
Frobenius norm is just a square root of sum of squares of elements of matrix (if we considered the matrix a regular vector, it would’be been its L2 norm). Thus it could be interpreted as the distance between matrices.
However, Frobenius norm is a good measure for the quality of our approximation not only because of its intuitiveness. A family of theorems in matrix analysis (such as Hoffman-Wielandt inequality) show that if matrix approximation converges to the true matrix in terms of Frobenius norm, then so do their eigenvalues and eigenvectors.
Another important way of representing the Frobenius norm is through the trace of Gram matrix, created out of the initial matrix: . We will heavily rely on this representation in this post.
An alternative option for the measure of quality of approximation is Kullback-Leibler divergence , which in matrix case evaluates to . In this case NMF bears similarities to various Bayesian methods, such as Probabilistic Latent Semantic Analysis (PLSA) method. However, I won’t delve into Kullback-Liebler-minimizing approach and will focus on the Frobenius norm as approximation quality metric.
NMF solver
One of the reasons of NMF popularity is its simple iterative solver.
In a series of alternating steps it updates the values of and matrices using the following update rules:
Let us derive this formula.
We want to solve the following optimization problem:
Or, equivalently, expressing Frobenius norm through trace notation, we have:
This is a minimization problem which can be solved through taking a derivative of a scalar function with respect to a matrix argument (the concept and mechanics of derivative of a scalar function with respect to a matrix argument is explained in detail here and here).
We will be doing a gradient descent, iteratively decreasing Frobenius norm with respect to matrix with fixed every odd step and with respect to matrix with matrix fixed every even step:
Here and are gradient step size.
Now let us decompose our trace into 4 terms and take its derivative and with respect to matrices and :
Taking derivative of each term separately:
(using the fact that )
(using the fact that )
(using the fact that )
Aggregating the results:
And carrying out similar calculations for we get:
Substituting this back into the original update formula (ignoring “2”, as it can be included into the gradient step):
Now the authors of the original paper suggest to set specific values of gradient update steps:
This leads us to the declared algorithm:
Here is a python implementation:
from typing import Tuple
import numpy as np
import numpy.typing as npt
class ConvergenceException(Exception):
def __init__(self):
Exception.__init__(self, "Iterations limit exceeded; algorithm failed to converge!")
def nmf(V: npt.NDArray, k: int, tol: float = 1e-4, max_iter: int=100) -> Tuple[npt.NDArray, npt.NDArray]:
"""An NMF solver implementation which approximates an n x p input matrix V
as a product W x H of n x k matrix W and k x p matrix H. This solver
minimizes Frobenius norm of the difference between V and W H and implements
an algorithm, described by Lee and Seung (2000) in:
https://proceedings.neurips.cc/paper/2000/file/f9d1152547c0bde01830b7e8bd60024c-Paper.pdf.
:param V: n x p matrix to be approximated with NMF low-rank approximation
:param k: rank of low-rank approximation
:param tol: threshold value of decrease in energy function between two consecutive iterations for the algorithm to
be considered converged
:param max_iter: maximum number of iterations allowed; if reached before convergence, ConvergenceException is thrown
:return: 2-tuple of two matrices:
- W - n x k matrix
- H - k x p matrix
"""
n = V.shape[0]
p = V.shape[1]
previous_energy = np.inf
next_energy = np.inf
iterations = 0
W = np.ones((n, k))
H = np.ones((k, p))
while (previous_energy - next_energy > tol) or next_energy == np.inf:
W_update = np.dot(V, H.T) / np.dot(W, np.dot(H, H.T))
W = W * W_update
H_update = np.dot(W.T, V) / np.dot(W.T, np.dot(W, H))
H = H * H_update
if iterations > max_iter:
raise ConvergenceException
else:
iterations += 1
previous_energy = next_energy
next_energy = np.linalg.norm(V - np.dot(W, H), 'fro') # calculate Frobenius norm
return W, HIf we run this code, the approximation is very decent:
import unittest
import numpy as np
from ..biclustering_lasso import nmf
class NMFTestCase(unittest.TestCase):
"""
python3 -m unittest biclustering_lasso.tests.test_nmf.NMFTestCase
"""
def test_nmf(self):
V = np.array([[2.1, 0.4, 1.2, 0.3, 1.1],
[2.1, 0.7, 2.3, 0.4, 2.2],
[2.4, 0.5, 3.2, 0.7, 3.3]])
W, H = nmf(V, k=2)
print(f"W = {W}")
print(f"H = {H}")>>> W
array([[0.49893966, 0.49893966],
[0.76064226, 0.76064226],
[1.02271335, 1.02271335]])
>>> H
array([[1.36102025, 0.33184111, 1.50013542, 0.31221326, 1.49381373],
[1.36102025, 0.33184111, 1.50013542, 0.31221326, 1.49381373]])
>>> np.dot(W, H)
array([[1.35813395, 0.33113738, 1.49695411, 0.31155116, 1.49064583],
[2.07049903, 0.50482475, 2.2821328 , 0.47496521, 2.27251571],
[2.78386716, 0.67875667, 3.06841706, 0.63860935, 3.05548651]])
>>> V
array([[2.1, 0.4, 1.2, 0.3, 1.1],
[2.1, 0.7, 2.3, 0.4, 2.2],
[2.4, 0.5, 3.2, 0.7, 3.3]])As you can see, np.dot(W, H) approximates V very well. And due to the fact that it is so easy to implement, it is
probably the favourite algorithm of your favourite bioinformatics student:

NMF as a special case of k-means
A less obvious application of NMF is data clustering. Turns out, k-means clustering is a special case of NMF.
Suppose that we have identified clusters among our data points .
We can interpret the rows of matrix as centroids of our clusters:
Then matrix can be made orthogonal non-negative, representing attribution of data points to clusters. E.g.:
Here matrix describes two clusters, the first contains data point {} and the second - {, }. If all the coordinates of the data are non-negative, this means that coordinates of all the cluster centroids are non-negative as well. is non-negative, too. So, all the requirements of NMF are satisfied.
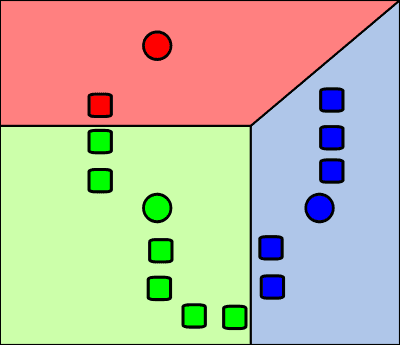
k-means solution with EM-like algorithm
In practice, k-means can be solved with a two-step iterative EM-like algorithm.
Initialize cluster centroids with random values (obviously, we can get smarter with initialization, but even random will do for now).
Each iteration of EM algorithm consists of two steps:
- E-step: assign each data point to the cluster with the nearest centroid
- M-step: re-calculate the coordinates of each centroid as a center of mass of the data points, which belong to its cluster
This algorithm converges, because there exists a non-negative monotonically decreasing (non-increasing) “energy” function, which decreases at each iteration, both on E-step and M-step.
The exact choice of the energy function could vary, and depending on the one selected, the algorithm takes new interesting interpretations. For instance, NMF with Kullback-Leibler divergence as energy function results in intepretaiton of NMF as probabilistic latent semantic analysi (PLSA) algorithm. We are going to use Frobenius norm as the energy function, which results in a multitude of truncated PCA/biclustering/spectral clustering interpretations.
Here is an implementation of k-means (with k-means++ initialization):
import math
import random
from typing import Tuple, Union
import numpy as np
import numpy.typing as npt
class ConvergenceException(Exception):
def __init__(self):
Exception.__init__(self, "Iterations limit exceeded; algorithm failed to converge!")
def k_means_clustering(
X: npt.NDArray,
k: int,
tol: float = 1e-5,
max_iter: int = 100,
energy: Union['KL', 'fro'] = 'fro'
) -> Tuple[npt.NDArray, npt.NDArray]:
"""A minimal implementation of k-means clustering algorithm.
:param X: n x p data matrix, where each point of data is a p-dimensional np.array
:param k: number of cluster centroids, we aim to find
:param tol: tolerance in energy; stop and return result, if the decrease in energy between 2 steps is below tol
:param max_iter: maximum number of iterations of the algorithm allowed; abort with ConvergenceException if exceeded
:param energy: monotonically non-increasing energy function to calculate (options: Kullback-Leibler, Frobenius norm)
:return: (centroids, clusters) - a 2-Tuple of 2 matrices:
- centroids - k x p matrix of cluster centroids
- clusters - n x k indicator vectors, which define a set of data points, which belongs to each cluster
"""
n = X.shape[0]
p = X.shape[1]
centroids = init_centroids(X, k)
clusters = np.empty(shape=(n, k))
iterations = 0
next_energy = np.Inf
previous_energy = np.Inf
while not (previous_energy - next_energy < tol):
clusters = e_step(X, centroids)
centroids = m_step(X, centroids, clusters)
if iterations > max_iter:
raise ConvergenceException
else:
iterations += 1
previous_energy = next_energy
next_energy = calculate_energy(X, centroids, clusters, energy)
return centroids, clusters
def init_centroids(X, k) -> npt.NDArray:
"""Initialization procedure for settings the initial locations of
centroids, based on k-means++ (2006-2007) algorithm:
https://en.wikipedia.org/wiki/K-means%2B%2B.
"""
n = X.shape[0]
p = X.shape[1]
centroids = np.zeros((1, p))
random_point_index = random.randrange(n)
np.copyto(centroids[0], X[random_point_index]) # use a random row of X matrix as a centroid
for _ in range(k-1):
# find closest centroid to each data point
clusters = e_step(X, centroids)
# construct probability distribution of selecting data points as centroids
distribution = np.zeros(n)
for index, data_point in enumerate(X):
# find the coordinate of 1 in clusters[index] - it will be the index of centroid
nearest_centroid_index = np.argmax(clusters[index]) # finds the location of 1
nearest_centroid = centroids[nearest_centroid_index]
# probability of a point being selected as a new centroid is ~ square distance D(point, centroid)
distribution[index] = np.dot(data_point - nearest_centroid, data_point - nearest_centroid)
# pick a data point to be the next centroid at random
new_centroid = random.choices(X, weights=distribution)
centroids = np.vstack([centroids, new_centroid])
return centroids
def e_step(X, centroids):
"""Assign each data point to a cluster with the nearest centroid."""
clusters = np.zeros(shape=(X.shape[0], centroids.shape[0]))
for data_point_index, data_point in enumerate(X):
nearest_centroid_index = 0
shortest_distance_to_centroid = np.infty
for index, centroid in enumerate(centroids):
direction = data_point - centroid
distance = math.sqrt(np.dot(direction, direction))
if distance < shortest_distance_to_centroid:
shortest_distance_to_centroid = distance
nearest_centroid_index = index
clusters[data_point_index][nearest_centroid_index] = 1
return clusters
def m_step(X, centroids, clusters):
"""Re-calculate new centroids based on the updated clusters."""
# divide each cluster element by the number of elements in it for averaging (e.g. [0, 1, 1] -> [0, 0.5, 0.5])
normalized_clusters = clusters.T
for index, cluster in enumerate(normalized_clusters):
np.copyto(normalized_clusters[index], cluster / cluster.sum())
normalized_clusters = normalized_clusters.T
# move each centroid to the center of mass of its respective cluster
new_centroids = np.dot(X.T, normalized_clusters).T
return new_centroids
def calculate_energy(X, centroids, clusters, energy: Union['KL', 'fro']) -> float:
"""Implementation of several energy functions calculation."""
if energy == 'fro':
result = np.linalg.norm(X - np.dot(clusters, centroids), 'fro')
elif energy == 'KL':
result = 0 # TODO
else:
raise ValueError(f"Undefined energy function type '{energy}'")
return resultLet us test our implementation:
import unittest
import numpy as np
from ..biclustering_lasso import k_means_clustering
class KMeansTestCase(unittest.TestCase):
"""
python3 -m unittest biclustering_lasso.tests.test_nmf.NMFTestCase
"""
def test_k_means(self):
X = np.array([[2.1, 0.4, 1.2, 0.3, 1.1],
[2.1, 0.7, 2.3, 0.4, 2.2],
[2.4, 0.5, 3.2, 0.7, 3.3]])
centroids, clusters = k_means_clustering(X, k=2)
print(f"centroids = {centroids}")
print(f"clusters = {clusters}")>>> centroids
array([[2.1 , 0.4 , 1.2 , 0.3 , 1.1 ],
[2.25, 0.6 , 2.75, 0.55, 2.75]])
>>> clusters
array([[1. , 0. ],
[0. , 0.5],
[0. , 0.5]])
>>> np.dot(clusters, centroids)
array([[2.1 , 0.4 , 1.2 , 0.3 , 1.1 ],
[1.125, 0.3 , 1.375, 0.275, 1.375],
[1.125, 0.3 , 1.375, 0.275, 1.375]])
>>> X
array([[2.1, 0.4, 1.2, 0.3, 1.1],
[2.1, 0.7, 2.3, 0.4, 2.2],
[2.4, 0.5, 3.2, 0.7, 3.3]])Again, we get a decent low-rank approximation of X matrix by k-means cluster np.dot(clusters, centroids).
Symmetric NMF
NMF is not unique. For instance, you could obviously insert a matrix and its inverse in between and :
.
Hence, there are plenty of options for additional constraints on and .
You could demand that one of them, or is orthogonal. This special case leads to k-means interpretation (where the orthogonal matrix represents clusters and the other one - coordinates of centroids).
Or you can demand that NMF is symmetric and . This special case is called symmetric NMF and will be considered further.
2. Symmetric NMF interpretation through k-means
It turns out that symmetric NMF algorithm can be interpreted as a variation of “soft” k-means clustering.
In “hard” k-means clustering each data point belongs to strictly one cluster. In “soft” clustering every point is assigned weights, which show how close (or likely to belong) it is to each cluster.
In “hard” clustering clusters matrix is orthogonal. As we’ll see further in this post, in “soft” clustering weights matrix is not orthogonal, but tends to be approximately orthogonal.
In order to establish correspondence between symmetric NMF and k-means I will first need a technical lemma, which shows that minimum of Frobenius norm of error of rank- matrix approximation coincides with the maximum of quadratic form of the approximated matrix. Moreover, in case of rank- matrix approximation via , minimum of Frobenius norm of error corresponds to a trace .
This fact will prove useful for all the 4 algorithms, described in this post.
Lemma 2.0. Minimum of Frobenius norm corresponds to the maximum of Rayleigh quotient
Assume that matrices and are orthogonal, i.e.
Then the following holds:
,
or, in case of rank , and single vectors and we get:
,
Let us show this result for the rank case (a pair of vectors) and then generalize to arbitrary rank.
.
Hence, attains its minimum when attains its minimum or attains its maximum.
Now consider case ( etc. works similarly):
.
Lemma 2.1. Symmetric NMF is equivalent to kernel K-means clustering
Consider a special case of NMF, when , called symmetric NMF. In this case we’re looking for an approximation:
And the goal is to find .
If we assume that is orthogonal (, where is identity matrix), then by Lemma 2.0 we immediately see that:
.
Lemma 2.2. Symmetric NMF matrix is near orthogonal
Interestingly, we might not need to explicitly impose the requirement that , yet still turns out to be approximately orthogonal, if we find it through a symmetric NMF.
Here the term corresponds to the minimization problem, similar to k-means. The term works almost like a constraint. Let’s focus on it:
,
where e.g. .
From the definition of Frobenius norm then .
Let us split this sum into two parts: diagonal elements and non-diagonal elements separately:
Minimization of the term essentially enforces approximate orthogonality, while the second term is responsible for normalization . This term attains minimum when all the norms of vectors are approximately balanced ().
3. Biclustering problem and quadratic programming/NMF
Another related problem is the problem of biclustering.
Suppose that you have a matrix with expressions of genes, measured in patients, and you want to find sub-groups of patients with similar patterns of expression (e.g. you’re looking for subtypes of cancer).
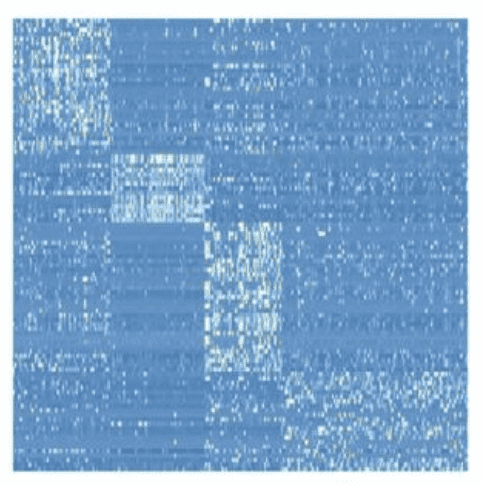
So, you want to simultaneously detect subsets of columns and subsets of rows, such that they explain e.g. a large chunk of variance in your data (the variance in a bicluster is expected to be low, though).
Equivalently, this problem can be re-formulated as detection of dense subgraphs in a bipartite graph

Lemma 3.1. Biclustering problem is equivalent to quadratic programming/NMF low-rank approximation of a Jordan-Wielandt matrix
Let us formalize the biclustering problem.
We need to find a pair of indicator vectors
such that
I call this bilinear programming, as we need to optimize the value of a bilinear form. In a more general case we might need to find matrices (, ) (i.e. multiple pairs (, ), potentially covering the whole matrix; vector pairs may intersect or may not, depending on the problem statement).
Turns out, we can re-formulate this bilinear optimization as a quadratic optimization problem. Let us put the vectors and on top of each other, concatenating them into a unified vector .
Replace the matrix with the following Jordan-Wielandt matrix:
Then our optimization problem is to find .
Again, if we want to find multiple biclusters, instead of a single vector , we use a whole matrix , and then our optimization problem takes a familiar form .
This problem already looks awfully familiar, right? Let us consider one more face of it.
4. k-means corresponds to spectral clustering
Another interesting interpretation of the same algorithm comes from spectral graph theory.
To get a taste of this field first, suppose that we have a graph that consists of multiple disjoint subsets.
It can be shown, that each disjoint connected component in this graph is an eigenvector of so-called graph Laplacian.
For example, consider this disjoint graph, its degree matrix , adjacency matrix and Laplacian :
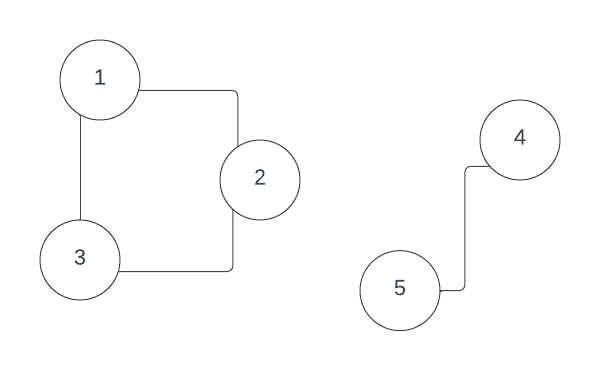
, ,
It is easy to see that vectors and , which define two connected components, are eigenvectors with 0 eigenvalue for graph Laplacian:
Now, instead of strictly disjoint graph, we might have a loosely disjoint one - with relatively dense subgraphs, interconnected with just a few “bridge” edges. We might want to find those dense sub-graphs. And they would serve as good clusters as well, if we re-formulated the problem as clustering?
Lemma 4.0. MinMax Cut solution through optimization of a quadratic form with Laplacian matrix
In 1993 Wu and Leahy suggested an algorithm of finding a minimal/maximal cut in graphs, based on spectral clustering.
The cut was meant to be the set of edges, that would split the graph into 2 halves, and , so that the sum of edges, which connect these two parts, is minimal: .
Speaking in terms of Laplacian and spectral graph theory, we can re-formulate MinCut optimization problem as follows. We introduce indicator vectors , where , if vertex and , if .
Now, you can see that if we defined some partition of our graph into halves and , adjacency matrix gets split into 4 blocks: block diagonal elements of the matrix represent nodes within and subgraphs, and off-diagonal elements represent :
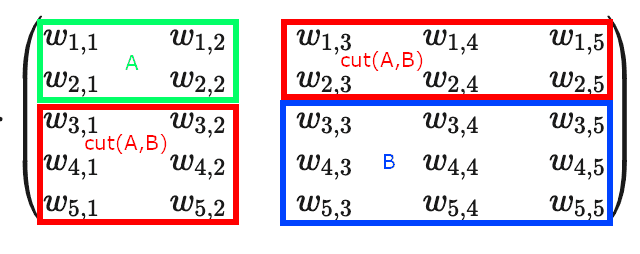
Now consider a quadratic form :
.
Now, take the degree matrix , create a similar quadratic form out of if:
.
If we now subtract the quadratic forms, we’d see that all edges, except by the members of , cancel each other out:
.
In other words, to minimize the , we need to find indicator vectors , such that they minimize the quadratic form , where is graph Laplacian. We just discovered another interesting connection with linear algebra and spectral graph theory, which is going to be instrumental a bit later.
For now, I shall notice that although MinMaxCut algorithm was enlightening, in its raw form it was prone to a fallacy of selecting a single most disconnected vertex as and cutting it off of the rest of the graph:
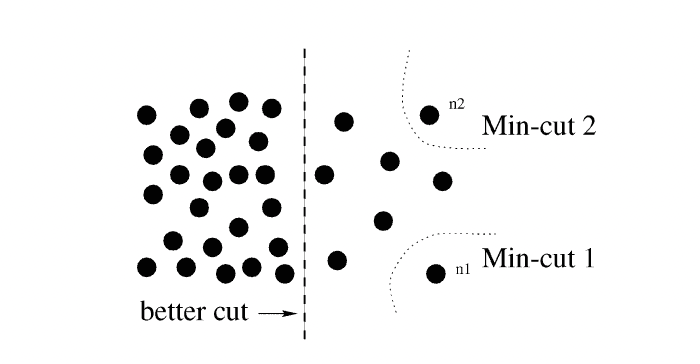
Lemma 4.1. Normalized Cut problems on a graph correspond to the k-means clustering problem
To address the problem of undesired behaviour of MinMaxCut, Shi and Malik (1997, 2000) came up with their (now famous) Normalized Cut algorithm. They tweaked the optimized function to cut away a sizable portion of the edges of the graph relative to the total weights of edges, kept within its halves:
, where .
If we take a look at the weighted adjacency matrix, representing the graph, and would cluster subgraphs and at diagonal blocks, we’d see that corresponds to the sum of weights of the off-diagonal blocks, while denominators and form full-width horizontal (or full-width vertical) blocks:
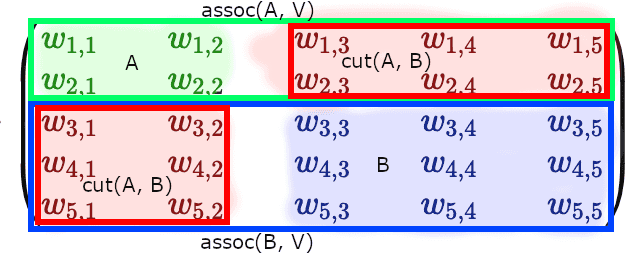
Shi and Malik use a bit different version of indicator vectors. Unlike MinMaxCut their indicator vectors are comprised of 0-1 coordinates : .
Then .
Now, if we take a look at the denominators, .
Shi and Malik then define a constant , such that and .
Then .
After that Shi and Malik define a ratio . Then they perform a long series of simplifications and show that:
.
Finally, Shi and Malik define a new variable and apply two changes to the resulting formula:
-
They notice that the denominator can be altered: .
-
They re-formulate the condition as a pair of conditions:
First equation in this pair is explained by the fact that by definition of the constant .
Hence, our optimization problem results in the following minimizer and two constraints:
Note that the minimized quantity is essentially a generalized Rayleigh quotient. Its solution is generalized eigenvectors:
The generalized eigensystem is solved through introducing a variable replacement:
Then we come to an eigenvectors equation with symmetrically normalized Laplacian matrix:
We aim to minimize . The smallest , and it corresponds to eigenvector . Hence, we are interested in the next smallest eigenvalue. Luckily for us eigenvectors of a symmetric matrix are orthogonal, too, making the condition tautological: .
Hence, we need to solve the problem:
We know, how to solve the first problem of finding Rayleigh quotient, but we don’t know, how to do this as a binary optimization problem, which arises due to the condition.
Shi and Malik just drop this binary value condition, find the second smallest eigenvector, and then binarize its coordinates (e.g. just check, if the value of a coordinate is closer to or and replace it with the closest).
If they want to find multiple cuts, they repeat the process on sub-graphs, found at the first step.
This post is inspired by my ongoing research on L1-regularized biclustering algorithms and sparse transformers, as well as discussions with Olga Zolotareva, Alexander Chervov, Anvar Kurmukov and Sberloga Data Science community. Many thanks to them.
References
- https://en.wikipedia.org/wiki/Non-negative_matrix_factorization#Clustering_property - NMF and clustering property
- https://ranger.uta.edu/~chqding/papers/NMF-SDM2005.pdf - the original paper on the equivalence of k-means and spectral clustering
- https://www.cs.utexas.edu/users/inderjit/public_papers/kdd_spectral_kernelkmeans.pdf - on correspondence between spectral clustering and k-means
- https://faculty.cc.gatech.edu/~hpark/papers/GT-CSE-08-01.pdf - on correspondence between sparse Nonnegative Matrix Factorization and Clustering
- https://www.researchgate.net/publication/2540554_A_Min-max_Cut_Algorithm_for_Graph_Partitioning_and_Data_Clustering - MinMax cut algorithm
- https://www.biorxiv.org/content/10.1101/2022.04.24.489301v1.full - fresh paper on spectral biclustering (source of images)
- https://www.youtube.com/watch?v=9fc-kdSRE7Y - derivative of trace with respect to a matrix
- https://en.wikipedia.org/wiki/Matrix_calculus#Scalar-by-matrix - derivative with respect to a matrix
- https://proceedings.neurips.cc/paper/2000/file/f9d1152547c0bde01830b7e8bd60024c-Paper.pdf - seminal Lee and Seung NMF solver paper
- https://stats.stackexchange.com/questions/351359/deriving-multiplicative-update-rules-for-nmf - summary of Lee and Seung NMF solver
- https://people.eecs.berkeley.edu/~malik/papers/SM-ncut.pdf - famous normalized cut algorithm by Shi and Malik (2000)
- https://people.orie.cornell.edu/dpw/orie6334/Fall2016/lecture7.pdf - on normalized Laplacian
- http://oa.ee.tsinghua.edu.cn/~zhangyujin/Download-Paper/E224%3DTKDE-13.pdf - NMF: a comprehensive review paper
- https://www.nature.com/articles/44565 - Lee and Seung original Nature paper on NMF

Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram