

Kernel methods and Reproducing Kernel Hilbert Space (RKHS)
August 03, 2021 38 min read
Kernel methods are yet another approach to automatic feature selection/engineering in the machine learning engineer's toolbox. It is based on theoretical results from the field of functional analysis, dating to 1900s and 1950s, called Reproducing Kernel Hilbert Space. Kernel methods, such as kernel SVMs, kernel ridge regressions, gaussian processes, kernel PCA or kernel spectral clustering are very popular in machine learning. In this post I'll try to summarize my readings about this topic, linearizing the pre-requisites into a coherent story.
Kernel methods and kernel trick
Suppose, you are trying to tell the difference between two sets of points with a linear binary classifier, like SVM, that can take decisions, using a linear decision boundary only.
What if your points are lying in a way that cannot be split by a single hyperplane in that space? E.g. there is no single line that could split the points, lying on a plane like a XOR function:
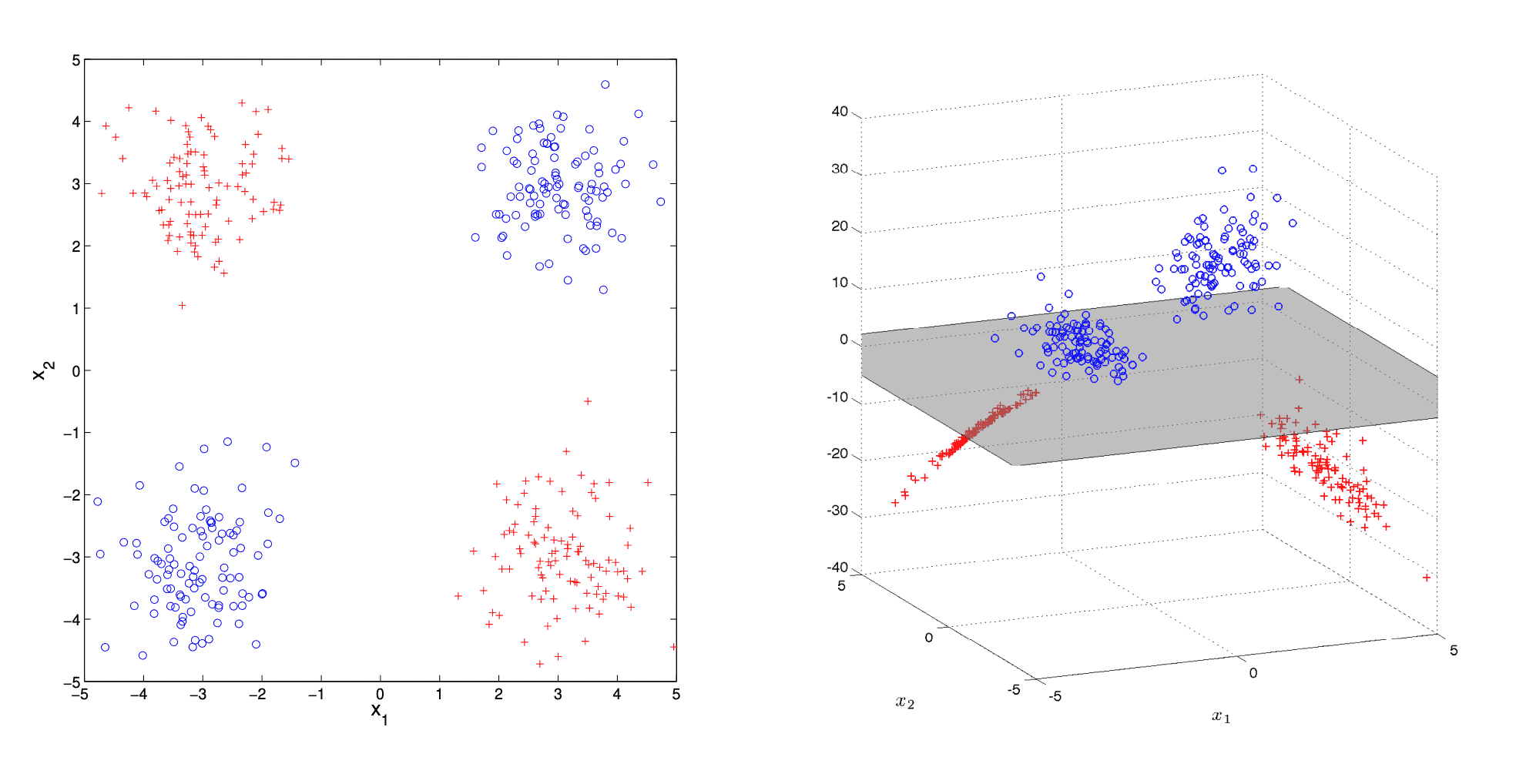
Feature maps
So what you can do is come up with extra features, made from the basic ones.
I.e. if each of your data points was something like a 2-vector , you could engineer a third feature to be, e.g. a product of the first two , and do the classification in 3D.
Such a mapping from the initial space to the new space is called a feature map and denoted .
Implicit features
Now, oftentimes you don’t need to express your features explicitly to perform the classification. Moreover, there is a way to make mathematics auto-magically engineer and select fairly complex features for you!
This magic is called Kernel trick, and it is widely applicable in machine learning. Many linear methods, based on least squares problem, can be “upgraded” with kernel trick to perform in a high-dimensional feature map space. This family of methods is called “kernel methods”. For example, ridge regression, PCA, SVM. Gaussian processes, important by themselves and for bayesian neural networks, also belong to this class.
To explain kernel trick, I will first formally state a general formulation of the optimization problem we solve in statistical learning theory, called Empirical Risk Minimization problem, then describe the basic least squares problem, and then will “kernelize” it.
General form of Empirical Risk Minimization problem in statistical learning
Don’t worry, Empirical Risk Minimization is just a fancy name for your typical statistical learning problem.
Suppose that we have a training set of points , where each point consists of a vector of features and a class label . If the set of points is infinitely large, we can denote it as some join distribution P(x,y).
We are trying to come up with some classification/regression function from a space of functions , so that approximates well enough to classify/predict value of each point correctly.
The error between our prediction and true class/value is measured by a loss function .
The risk , associated with a choice of classification/regression function is measured as expectation of loss function over all the data points:
Thus, the optimal function (let us denote it with a hat ) would be the one to minimize the risk:
Often you would also want to add some kind of regularization term , e.g. L2-regularization ), with some weight into this equation in order to prevent from overfitting the data:
In case the amount of data available is finite (as is normally the case), the integral becomes a sum:
Example: simple regression problem with basic least squares
Recall, how the least squares work in case of normal features.
Let be the x matrix of data (e.g. n genes, p patients),
where are n-vectors, corresponding to each element of data (e.g. gene expressions for the patient ).
Let be the vector of results and be the vector of weights of factors. So, our prediction is .
The aim is to minimize the following sum of squares of prediction errors:
,
so that the optimal weights are:
We solve this minimization problem by taking the derivative and equating it to 0. In my opinion this is an abuse of notation, because we use a whole vector as independent variable, and we should’ve written equations instead for each :
Hence, .
Now, if the matrix were a full-rank non-singular matrix, we could’ve solved this equation, finding a unique solution: .
But note that is a rectangular, not a square matrix, thus, we don’t simplify this expression, as we cannot guarantee that is invertible.
Consider an example. Let . Then .
This matrix has rank 2: you can see that the third column of this matrix is a linear combination of the first two: .
Hence, the equation will either have no solutions, or have a whole linear space of dimensionality 1 of solutions.
To see this, consider another example, a matrix .
If we were to solve , this system obviously has no solutions.
If we were to solve , this system has a whole line of solutions .
Expression is called Moore-Penrose pseudo-inverse matrix.
The x matrix is often called a covariance matrix.
It is a Gram matrix by construction, and, thus, is positive (semi-)definite with positive/non-negative eigenvalues.
Kernel trick
Now, we shall replace the matrix of basic features with matrix of advanced features, where each row of length , corresponding to gene expressions of a single patient, is replaced by a row of feature maps of length of feature maps of those gene expressions:
Accordingly, the estimation function is replaced with , such that (again, the vector of weights is now -dimensional).
x positive-definite symmetric covariance matrix is replaced with a x positive-definite symmetric matrix . Note that can be infinite, in which case matrices and become infinite-dimensional.
Later in this post I am going to show that when we are looking for our function , we can actually get rid of an explicit in its expression and make depend only on the kernel matrix .
We can already see that function . A more general form of this result is known as Representer theorem (see below).
To get a feel of how this works, consider a nice special case.
If we assumed that is invertible, which might not be true, then .
Moreover, if both and were invertible, our pseudo-inverse matrix could be represented differently:
Denote kernel matrix . Each element of that matrix can be expressed as . Then:
Our is a row p-vector, corresponding to a single row of matrix , .
Multiplication of a vector by inverse matrix results in a one-hot vector (where every coodinate is 0, except by i-th, which is 1).
Thus, anticlimactically, . For previously unobserved data points , though, it would produce meaningful results. However, in reality , and one of the matrices or is usually singular and cannot be inverted. This case is considered later.
Another notation convention is to denote as a column p-vector . Hence, our .
Tikhonov (L2) regularization and Woodbury-Sherman-Morrison formula
In reality, the number of samples in your data matrix is rarely equal to the number of factors/features .
In case of kernel ridge regression, for many kernels the number of features is infinite (see RBF kernel example below).
If , is a non-full rank matrix with lots of zero eigenvalues, thus, its inverse does not exist.
However, in order to overcome this problem, we can add a Tikhonov regularization term: , effectively increasing all the matrix eigenvalues by and thus making it invertible.
After that we apply Woodbury-Sherman-Morrison formula to invert the regularized matrix and express the solution of kernel ridge regression through kernel matrix :
So, yes, if not for the regularization term, this formula would’ve just selected from outputs vector as an estimate of . However, addition of regularization to the kernel matrix complicates this expression.
Anyway, we end up with an explicit solution of KRR through kernel matrix and regression outputs and through mathematical magic avoid (possibly infinite-dimensional) feature space vectors .
Example: Radial Basis Functions (RBF) kernel
To give this idea a practical sense, let us consider a popular Radial Basis Functions (RBF) kernel, based on Gaussian distribution.
If we had and vectors of input features, the RBF kernel for them would look like this:
To see how this kernel produces feature maps, let us decompose it into separate multipliers. For now let us assume for shortness of notation, as it doesn’t affect the general idea.
We’ve just shown, how to split RBF kernel into an inner product of feature maps of each data point. Note that the sum is actually an infinite series - index runs to infinity. It would not be possible to explicitly write out feature maps.
Reproducing Kernel Hilbert Space formalism
Previously we’ve seen some practical examples of how kernelization can help us automatically engineer features to make our linear methods much more powerful. With kernel trick we can automatically generate complex (e.g. polynomial) features out of our basic ones, and our linear methods, such as linear regression, SVMs, PCA, Fisher discriminant analysis, spectral clustering etc. would become so much more powerful.
However, there is a whole layer of theoretical foundation behind this, that allows to prove that kernel methods are applicable to a wide range of kernels. Turns out that each kernel gives rise to a whole space of functions, called Reproducing Kernel Hilbert Space. This topic requires a pretty strong background in functional analysis, unfortunately.
There are 4 words and 3 concepts in Reproducing, Kernel Hilbert spaces. I’ll first explain the meaning of each of them separately, providing the missing context, and then will consider them together. RKHS is a beast with multiple faces, so you can approach it from different perspectives and then find out that they are all interconnected - quite a typical situation for the kaleidoscope of mathematics. I’ll discuss those approaches in the second part of the post.
Integral transform and its kernel
The term “kernel” here in Reproducing Kernel Hilbert Space is used in the context of integral transforms, which has absolutely nothing (1, 2) to do with the kernel of homomorphism or linear transformation.
As an example of integral transformation consider a sound signal - you have a WAV-file, which is a function in the time domain, which equals to the air pressure, produced by your headphones at every given moment of time, while they play the signal. WAV-files are typically huge, so you want to compress the singal by decomposing the sound into harmonics of various frequencies and sacrificing the very high-frequency ones, as 1) their amplitudes are typically very low and 2) human ear can’t hear them anyway. This is more or less how MP3 files work and that’s why they are much smaller than WAVs.
So, you do a Fourier series decomposition of your initial signal , which is an integral transform:
, where is the amplitude of harmonic with frequency .
Speaking generally, what we did here was an integral transform from a function in the time domain to a function in the frequency domain.
This is formally written as:
Here is an integral transform of function , which results in a function in a different domain , and is the kernel of integral transform. In case of Fourier transform our kernel was .
RKHS deals with some special case of kernels, which possess some nice and helpful properties, which we shall discuss later.
Hilbert spaces
Next term in the Reproducing Kernel Hilbert Space abbreviation, that we are going to explore, is “Hilbert space”.
Hilbert space is a slightly more abstract concept, that typical Euclidean space we all are used to.
Speaking informally, in regular Euclidean spaces we are considering finite-dimensional vectors.
Hilbert spaces are a bit more general, because they allow the vectors to be infinite-dimensional. The motivation can be very simple.
Imagine a function, e.g. . You can measure its values in discrete points e.g. {x=-2, x=-1, x=0, x=1, x=2} and get a vector of funciton values {f(-2)=4, f(-1)=1, f(0)=0, f(1)=1, f(2)=4}.
Now, suppose that you have infinite number of points, where you measure the value of your function. So, instead of a finite-dimensional vector, you get a continuous vector. Such infinite-dimensional vector, representing a function, is a single point in a space that is called a Hilbert space.
Moreover, you can define distances and angles on the Hilbert space, by introducing dot product constructuon. A dot product between two functions and would be:
Hence, you can define “length” (or, rather, its formal generalization, called norm) of your infinite-dimentional vector as:
And the angle between two functions and then can be defined as .
Note, how this definition is useful for Fourier transforms - you can treat Fourier transform of a function as a dot product of that function and a Fourier harmonic:
Angles are super-important, because you can say that some functions are orthogonal to each other (e.g. Fourier harmonics are orthogonal to each other - you may prove it yourself). Having a set of orthogonal functions, such as Fourier harmonics, is super-useful, because you can use it as a basis in your Hilbert space, and easily represent other functions as a linear combination of your basis functions.
Hierarchy of topological spaces
If we were to address the formal definition of Hilbert space, we would note that it is defined as
- complete
- topological vector space
- with a dot product and a norm, generated by the notion of dot product
We’ve already discussed the concept of (3) dot product and norm. What’s left is (1) completeness and the notion of (2) topological vector space.
Mathematicians introduced more and more abstract concepts of spaces, which could be treated similarly to hierarchies of inheritance in object-oriented programming.
Let’s take a look at a diagram of various spaces, they defined:

As you can see, the Hilbert space has a whole hierarchy of parents. I’ll consider only the most important ones:
- (1a) Vector spaces or linear spaces - spaces of objects, that can be multiplied by a scalar or added, while preserving linearity
- (1b) Topological spaces - spaces, where the notion of topology (basically, the relation of neighbourhood between points) is defined; note that neighbourhood is more abstract concept than the concept of length - you can define the notion of neighbourhood on a rubber band, and while the distances between its point can be altered, as you stretch it, the notion of neighbourhood is preserved
- (2) Metric spaces - topological vector spaces (multiple inheritance of topological and vector spaces), with the notion of distance between two points, that induces the topology
- (3) Normed vector spaces - metric spaces with the notion of norm (generalization of length) of a vector/point
- (4) Banach spaces - complete normed vector spaces; completeness means that if a Cauchy sequence converges to some limit, that limit is also an element of the space - this is a valuable property for proving theorems in functional analysis
- (5) Hilbert spaces - banach spaces with the notion of dot product/inner product that induces the norm
Reproducing property
Informally speaking, the definition of reproducing property is that if two functions from the Hilbert space are close in norm, it guarantees that evaluations of those functions at any point are also close:
, where is a constant specific for point .
Operation of evaluation of a function is defined by an evaluation funcional that accepts any funciton on input and returns its value at the point . As we just stated infromally, our evaluation functional is continuous, hence, bounded.
Using that fact, we can apply Riesz-Frechet representation theorem, which states that there is a representation of this functional as an integral with some function :
Now, the function is itself a function in RKHS, so we can apply evaluation functional to it, but at a different point:
If our inner product for functions and were defined just as a regular integral , then evaluation functional is a trivial function, which equals 1 in and 0 everywhere else.
However, we may define custom inner products (see an example of inner product with roughness penalty in the lecture by Arthur Gretton).
In this case reproducing property becomes non-trivial, and the custom inner product is the reason to define a custom Hilbert space.
Properties of the kernel function follow from the properties of inner product. It is symmetric, because the inner product is symmetric, and it is positive-definite, because, again, the inner product is positive definite. For the definition of positive definiteness for an operator, please see Mercer theorem section below.
Symmetry (follows from symmetry/conjugate symmetry property of inner product):
Positive semidefiniteness: for any set of numbers the following expression is required to be non-negative:
There is an inverse statement, called Moore–Aronszajn theorem - every symmetric, positive semidefinite kernel gives rise to a unique Hilbert space. I leave the proof up to wikipedia. Note that only the kernel is unique for RKHS, feature map must not be unique for RKHS.
Representer theorem
Remember, we previously showed an example of how to represent the optimal solution of Empirical Risk Minimization problem via an inner product of some feature map with a set of coefficients?
This is actually a theorem, called Representer theorem.
In its general form it is as follows. If we are seeking the solution of an optimization problem:
,
where is a strictly monotonically increasing function on and the solution is required to be a function from the class of feature maps , corresponding to a kernel , then the solution can be represented as .
We’ve already seen an example of how this works before in case of kernel regression. This is a more general statement that claims that even if we are optimizing a more or less arbitrary functional and use a rather wide class of regularization functions (as long as they are monotonic), the kernel method still works.
The proof is as follows:
Suppose that we found a way to decompose our function into a sum of two orthogonal parts: one part is the subspace, covered by all the feature map functions , and the other part is its orthogonal complement :
If we were to evaluate this function at a specific point , the reproducing property and orthogonality of would kick in:
Hence, when we use this formula for to evaluate the loss in our estimator, the loss does not depend on . As for the regularization term:
Optimum of is achieved when is 0 (or minimum) due to monotonicity of regularizer in its argument. Hence,
, which proves the theorem.
Mercer theorem
Finite-dimensional case: Gram matrix
To get an intuition of Mercer theorem let us first consider a discrete case, where our operator is just a real-valued matrix.
In discrete case a matrix is called a Gram matrix, if it is constructed as a multiplication of a data matrix with its inverse:
A matrix like this has 2 important properties: it is symmetric and positive (semi-)definite.
Moreover, the reverse is also true: if the matrix is positive semidefinite, it is always a Gram matrix of dot products of some matrices , called realizations: . This statement is a finite-dimensional version of Mercer’s theorem. I will first explore the properties of a Gram matrix, constructed as a dot product matrix, and after that will proof the discrete analogue of Mercer theorem.
Symmetry
If out matrix of dimensionality is symmetric (so that its elements across the diagonal are identical), it means that its eigenvectors are orthogonal and form an orthogonal matrix , where each column of such a matrix is an eigenvector , and eigenvectors are orthogonal, so that if and if .
This leads to eigenvalue decomposition of our matrix as:
,
where is the diagonal matrix of eigenvalues corresponding to eigenvectors : , and we use the fact that eigenvector matrix is orthogonal, so that .
Hence, we can use an alternative representation of eigenvalue decomposition through outer product:
For more details on the topic, see this post.
Positive (semi-) definiteness
Positive definite matrix is such a matrix, that being considered as a quadratic form matrix, it always produces a positive (for positive definite) or non-negative (for positive semidefinite) scalar:
for any vector
This leads to the following consequence:
As Gram matrix is symmetric, its eigenvalues are real (again, see this post). Moreover, all of them have to be non-negative, because if any eigenvalue were negative, it would mean that for en eigenvector :
, and ,
as square of vector length is positive, and is negative by proposal), which contradicts the definition of positive semidefinite matrix.
Note that positive definite matrices generally don’t have to be symmetric. E.g. is positive definite, because:
But it is not symmetric. See this StackOverflow post.
Non-full rank Gram matrices
Interestingly, an x Gram matrix is oftentimes not a full-rank matrix.
Suppose, that realization matrix , and we were looking for the Gram matrix
.
Again, you can use the perspective of outer product to see that matrix has the rank of 2:
.
You can tell that there are only 2 linearly independent rows in this matrix, so the third row can be represented as a linear combination of the first two rows.
What if it is the other way around, and ?
Then your Gram matrix is is a full-rank matrix, and realizations are not unique.
However, realizations are non-unique only up to an orthogonal transformations. For instance, if you know a matrix of realizations of x , and you want to find a realization matrix of by dimensionality, it will have a form of = , where is an x matrix with orthogonal columns:
.
“Discrete Mercer theorem” proof
Now it is time to prove the inverse statement: if a matrix is positive definite and symmetric, it is a Gram matrix for some vector realizations.
The proof is constructive and pretty simple.
Our x matrix must have an eigenvalue decomposition , which we can split into 2 multipliers:
, where .
Hence, is a realization matrix. Note that if is strictly positive definite, all the eigenvalues in matrix are positive. If it is non-negatively definite, some of the eigenvalues are 0, the matrix is non-full rank, and the matrix is rectangular with 0 rows rather than square.
Infinite-dimensional case: positive-definite kernel
Now, we can generalize this statement to infinite-dimensional case. Let no longer be elements of a symmetric matrix, but instead become a kernel function of a self-adjoint operator instead.
Then, if our operator also is positive (semi-) definite, we can consider it as an analogue of a Gram matrix. Then the definition of positive (semi-) definite naturally extends the definition of positive (semi-) definite matrix.
for any numbers and all finite sequences of points / .
Then Mercer’s theorem states that the eigenfunctions of form an orthonormal basis in , their corresponding eigenvalues are non-negative, and the kernel has a representation as a converging absolutely and uniformly series:
The proof builds upon the fact, that our operator is a compact operator. For compact operators eigenfunctions form a discrete orthonormal basis by the spectral theorem, making the rest of the proof similar to finite-dimensional case.
For more details on spectral theorems in functional analysis, see this post.
References
- https://www.youtube.com/watch?v=XUj5JbQihlU - incredibly fun and comprehensible talk by enthusiastic Yaser Abu-Mostafa from Caltech
- https://www.gatsby.ucl.ac.uk/~gretton/coursefiles/Slides4A.pdf - presentation by brilliant Arthur Gretton from UCL
- https://www.youtube.com/watch?v=alrKls6BORc - talk by Arthur Gretton, corresponding to the presentation
- https://medium.com/@zxr.nju/what-is-the-kernel-trick-why-is-it-important-98a98db0961d - example of use of kernel trick
- https://en.wikipedia.org/wiki/Reproducing_kernel_Hilbert_space - a decent and helpful explanation from wikipedia
- https://arxiv.org/pdf/2106.08443.pdf - a good survey on kernel methods in ML
- http://math.sfu-kras.ru/sites/default/files/lectures.pdf - a course of lectures on functional analysis (in Russian)
- https://stats.stackexchange.com/questions/123413/using-a-gaussian-kernel-in-svm-how-exactly-is-this-then-written-as-a-dot-produc - a nice question, explaining why RBF kernel is actually a RKHS kernel
- https://people.cs.umass.edu/~domke/courses/sml2011/03optimization.pdf - a decent write-up about Empirical Risk Minimization problem and introduction to optimization in general
- http://web.eecs.umich.edu/~cscott/past_courses/eecs598w14/notes/13_kernel_methods.pdf - on Representer theorem and kernel methods in geenral
- https://alex.smola.org/papers/2001/SchHerSmo01.pdf - original 2001 paper by Smola, Herbrich and Scholkopf on generalized Representer theorem
- https://www.iist.ac.in/sites/default/files/people/in12167/RKHS_0.pdf - another good write-up on RKHS and kernel methods
- https://www.mdpi.com/2227-9717/8/1/24/htm - a very helpful review of kernel methods and kernel trick
- https://www.youtube.com/watch?v=JQJVA8ehlbM - a good step-by-step video introduction of kernel methods
- https://www.youtube.com/watch?v=rKiy6wEiQIk - Riesz-Frechet representation theorem
- http://people.eecs.berkeley.edu/~bartlett/courses/281b-sp08/7.pdf - a good short text on RKHS and reproducing property with examples
- https://www.face-rec.org/interesting-papers/General/eig_book04.pdf - a good survey of eigenproblems, including kernel methods applications, in ML
- https://www.kdnuggets.com/2016/07/guyon-data-mining-history-svm-support-vector-machines.html - Isabelle Guyon on (re-) invention of kernel trick by her and Vapnik in 1991
- http://www.mathnet.ru/php/archive.phtml?wshow=paper&jrnid=at&paperid=11804&option_lang=eng - 1964 Aizerman, Braverman and Rozonoer paper on proto-kernel trick (mostly in Russian)
- https://users.wpi.edu/~walker/MA3257/HANDOUTS/least-squares_handout.pdf - a nice, but partially wrong text about rank and singularity of Gram matrix and uniqueness/existence of least squares solution
- https://datascience.stackexchange.com/questions/103382/kernel-trick-derivation-why-this-simplification-is-incorrect/103427#103427 - answer to my question on Stack Overflow
- http://www.seas.ucla.edu/~vandenbe/133A/lectures/ls.pdf - good practical examples of least squares with p >> n, non-singular matrix A, ill-conditioned equations etc.
- https://gregorygundersen.com/blog/2020/01/06/kernel-gp-regression/ - Gregory Gunderson on kernel ridge regression comparison with Gaussian processes and on Woodbury identitiy derivation
- https://gregorygundersen.com/blog/2018/11/30/woodbury/ - Gregory Gunderson on Woodbury identity
- https://web2.qatar.cmu.edu/~gdicaro/10315-Fall19/additional/welling-notes-on-kernel-ridge.pdf - Max Welling on kernel ridge regression, regularization and Woodbury-Sherman-Morrison identity
- https://www.quora.com/Are-the-eigenvalues-of-a-matrix-unchanged-if-a-constant-is-added-to-each-diagonal-element - why L2 regularisation makes the matrix non-singular
- https://www.chebfun.org/examples/stats/MercerKarhunenLoeve.html - a post on Mercer kernel and Karhunen-Loeve expansion
- https://en.wikipedia.org/wiki/Hilbert_space - one of the best articles on mathematics, I’ve ever seen on wikipedia
- https://en.wikipedia.org/wiki/Representer_theorem
- https://en.wikipedia.org/wiki/Positive-definite_kernel
- https://en.wikipedia.org/wiki/Reproducing_kernel_Hilbert_space
- https://en.wikipedia.org/wiki/Definite_matrix#Decomposition
- https://en.wikipedia.org/wiki/Gram_matrix
- https://en.wikipedia.org/wiki/Empirical_risk_minimization
- https://en.wikipedia.org/wiki/Kernel_principal_component_analysis
- https://en.wikipedia.org/wiki/Integral_transform
- https://en.wikipedia.org/wiki/Radial_basis_function_kernel
- https://en.wikipedia.org/wiki/Least_squares
- https://en.wikipedia.org/wiki/Linear_least_squares

Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram