Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past.
Conjugate gradients is one of the most popular computationally effective methods, used to solve systems of linear equations. Along with other Krylov space methods it can also be used for finding eigenvalues and eigenvectors of a matrix.
System of linear equations as a quadratic optimization problem
In case A is a Gram matrix (i.e. symmetric and positive definite), so that its eigenvalues are real and positive, it
is useful to think about solution of a system of linear equations Ax=b in terms of an equivalent
quadratic problem of finding a minimum of a quadratic function, given by a quadratic form:
x∗:Ax−b=0⟺x∗=argxminϕ(x)=xTAx−bTx
Quadratic form xTAx represents ellipsoid, eigenvectors {ei} of matrix A are axes, eigenvalues
{ei} are lengths semi-axes, difference between the optimal solution and current point is x∗−x,
residue vector r=Ax−b=Ax−Ax∗ will be discussed later.
Naive approaches
How to solve a system of linear equations computationally?
We shall briefly consider two naive approches: coordinate descent and steepest descent, before discussing conjugate
gradients and their advantages.
Coordinate descent
First, let us look at the simplest approach: coordinate descent. I.e. we iteratively choose coordinates of the vector
xi and minimize the value of function ϕ(x) in that coordinate by solving ∂xi∂ϕ(x)=0.
Convergence
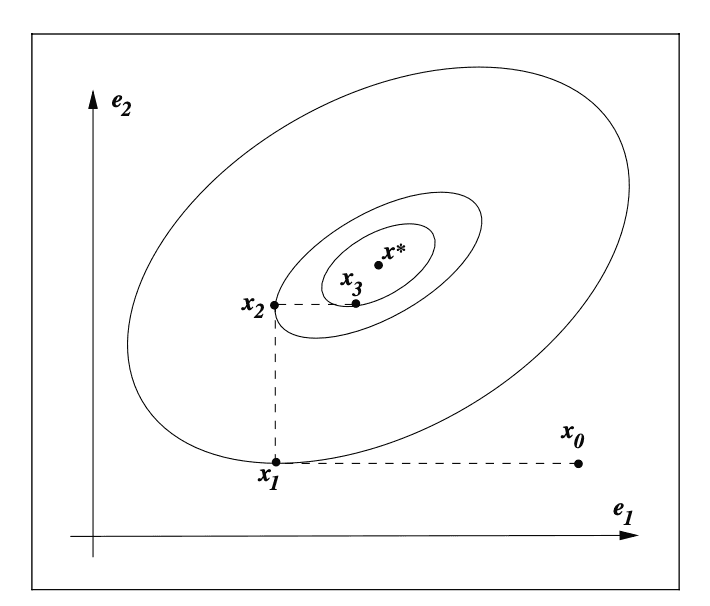
Coordinate descent clearly does not guarantee convergence in N steps:
Coordinate descent. In this example we have a 2D vector x, and coordinate descent does not converge to the solution x∗ in 2 steps.
Steepest descent
A smarter approach is steepest descent.
At each step of coordinate descent we calculate the gradient vector ∇ϕ of function ϕ(x) and use it as
the direction of descent.
Here and below I will denote d the direction vector for descent. If we are speaking of multiple steps, I will denote
it as di. In case of the steepest descent at each step di=∇xi, where xi is the approximation of
solution x∗, obtained at i-th step, starting from an initial approximation x0.
If we are currently at the point x, we shall move to some point x+αd, where α is the step. We know
the direction, but how do we find the optimal step α of descent?
Length of the step is optimal, when the function ϕ(x+αd) is minimal in some point x+αd. It means
that directional derivative ∂d∂ϕ=0 and the isolevels of the function
ϕ(x)=xTAx−bTx become tangent to the direction d of descent.
Line search. We start from the point x (defined by a vector, starting from origin) and start searching in the direction d
for an optimal length α of d vector, so that the directional derivative of quadratic function ϕ(x) is 0
there, i.e. direction vector is tangent to isolevels of function ϕ(x) at that point.
Speaking in terms of multivariate calculus ⟨d,∂x∂ϕ⟩=0.
Simplifying this expression, we obtain the step length α:
dT(A(x+αd)−b)=0
dTAx+αdTAd−dTAd−dTb=0
α=−dTAddT(Ax−b)=−dTAddTr
Now our steepest descent algorithm is fully defined. By the way, this formula for step length α is going to be
useful below.
Convergence
Convergence rate of steepest descent varies. For instance, it might converge in one iteration, if A is diagonal and
all of its eigenvalues are equal:
Perfect convergence of steepest descent. If matrix A is diagonal with equal eigenvalues, isolevels are spheres and steepest descent converges in 1 iteration.
However, in general we cannot guarantee fast convergence for steepest descent. E.g. if the matrix A is ill-conditioned,
i.e. the difference in magnitude between its largest and smallest eigenvalues is big, steepest descent will start jumping
from one side of the ellipsoid to the other.
Poor convergence of steepest descent. If we have an ill-conditioned matrix, so that even one eigenvalue of matrix A is much smaller than other eigenvalues of matrix A, the ellipsoid isolevels look like a ravine, and gradient jumps off the sides of the ravine. Image from J.R.Schewchuk book.
Hence, convergence rate is related to condition numbers κ of the matrix. One can actually derive a formula for
convergence rate:
Exact derivation of this fact is somewhat tedious (although, not so hard for understanding) and can be found in J.R. Schewchuk tutorial, part 6.2.
Conjugate directions and conjugate gradients
As we’ve seen convergence of neither coordinate descent, nor steepest descent in N steps is guaranteed.
Here we discuss a better approach, conjugate directions, which will converge in N steps or less. It has a special
case, conjugate gradients, which is even more computationally efficient.
Let us start with an example of orthogonal axes and then transition to a general case.
Orthogonal axes
Consider the case when all the eigenvectors of our surface are parallel to the coordinate axes. In such a case matrix A
is diagonal and performing line search along the coordinate axes guarantees convergence in N iterations.
If matrix A is diagonal, line search along the conjugate directions converges in N steps. Image based on J.R.Schewchuk.
However, in general case we cannot rely on orthogonality of axes. If eigenvectors of matrix A are not orthogonal and
parallel to coordinate axes, this approach won’t work and line search along orthogonal directions would not work.
A-orthogonality
Instead of orthogonality, we introduce the notion of A-orthogonality:
⟨a,b⟩A=0⟺⟨Aa,b⟩=0⟺⟨a,Ab⟩=0
We will apply two transformations of coordinates.
First, apply eigen decomposition of A:
A=EΛE−1, where E is the matrix of eigenvectors (each eigenvector is a column-vector) and E is orthogonal, because eigenvectors
of symmetric matrix are orthogonal; Λ is the diagonal matrix of eignevalues, where each eigenvalue λi
is known to be real, positive and related to a corresponding singular value σi as λi=σi2.
⟨Aa,b⟩=bTAa=bTEΛE−1a
Use the fact that E is orthogonal for symmetric matrix A, hence, ET=E−1. Hence, (ETb)T=bTE=βT, ETa=α.
What did we do? We changed the coordinates, so that coordinate axes are now the eigenvectors E.
In these coordinates vector a has coordinates α and vector b has coordinates β.
What did we do here? We stretched our coordinate axes by their respective eigenvalues λi, transforming our vectors α into Λ1/2α=Λ1/2E−1a and
β into Λ1/2β=Λ1/2E−1b.
Eigenvectors, forming the semi-axes of ellipsoids, upon this change of coorindates take identical lengths, so that our ellipsoids become spheres.
So, how does A-orthogonality work: first we go from original coordinates to coordinates, where axes E are eigenvectors of A.
We apply this transform to both a and b vectors, resulting in their eigendecomposition vectors E−1a and E−1b.
Second, we come to a coordinate system, where isolevels are spheres. In these coordinates resulting vectors Λ1/2E−1a and Λ1/2E−1b must be orthogonal.
A-orthogonality: vectors that are A-orthogonal become orthogonal, if we make two changes of coordinates: first, we make eigenvectors the axes of our coordinate system, obtaining image (a); second, we stretch coordinate axes by eigenvalues, so that our isolevels become concentric spheres, resulting in image (b). Image from J.R.Schewchuk.
Conjugate directions
Let us prove the guarantees of convergence for conjugate directions algorithm in N steps.
Consider a descent algorithm, which uses vectors {di} as descent directions and step sizes αi=−diTAdidiTri, where ri=Axi−b is the current residue.
xn=x0+α0d0+α1d1+...+αn−1dn−1
We want to prove that if {di} are conjugate directions, then xn=x∗.
Indeed, we know that vectors {di} span the whole space. Hence, there exist coefficients {σi}, such that
we can come to the desired solution point x∗ walking the directions:
Consider the definition of conjugate directions: PTAP=D, where D is any diagonal matrix, P is the matrix of conjugate
directions row-vector (orthogonal).
A=PDPT
EΛET=PDPT
EΛ1/2=PD1/2
P=EΛ1/2D−1/2=E(ΛD−1)1/2
Conjugate gradients
How do we obtain conjugate directions in practice?
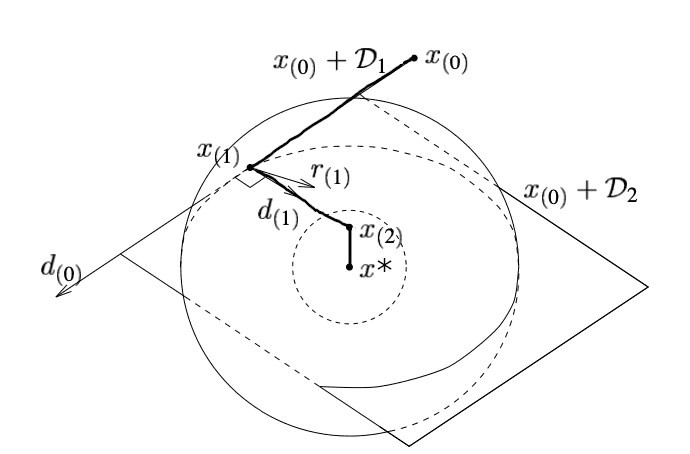
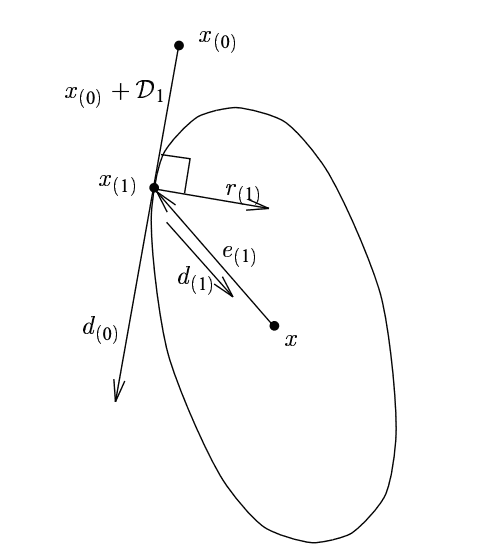
Simple and straightforward approach: let us use neg-gradients as directions: di+1=−ri+1=−A(xi+1−b). Problem is,
our “conjugate” directions are not conjugate. diTAdi+1=0, directions are not A-orthogonal (although, by the
way, we know that di+1 is orthogonal, not A-orthogonal to the previous search direction due to tangency of search
direction to isolevels at the point xi+1.
Conjugate directions in 2D. Note that r(1) is
orthogonal to d(0) and e(1) is A-orthogonal to d(0). Image from J.R. Schewchuk.
So, we correct the gradient direction by subtracting di with some coefficient to A-orthogonalize di+1 and di:
We know that di+1 is orthogonal to each of the previous directions {d1,...,di−1}.
Hence, ri+1 is already orthogonal to {d0,...,di}.
But more importantly for conjugate gradients, it is not only orthogonal, but also A-orthogonal to {d0,...,di−1}!
xi+1=xi+αidi
ri+1=ri+αiAdi
αiAdi=ri+1−ri
Pre-multiply this with rkT: αirkTAdi=rkTri+1−rkTri.
The following cases arise: ⎩⎨⎧k<i:rkTAdi=0k=i:riTAdi=−riTrik=i+1:ri+1TAdi=ri+1Tri+1
Hence, ri+1 is already A-orthogonal to dk for k<i. To A-orthogonalize di+1 derived from ri+1, all we need to do is to orthogonalize it with respect to di. This greatly simplifies
the calculation process and saves us a lot of memory:
di+1=−ri+1+βdi
Calculation of β is evident from A-orthogonality of di+1 and di: pre-multiply this expression with
diTA:
diTAdi+1=−diTAri+1+βdiTAdi (all other dkTAdi=0)
diTAri+1=βdiTAdi
β=diTAdidiTAri+1
This is just a special case of Schmidt orthogonalization.
Krylov space
One more important aspect: assume x0=0 and consider −r0=b−Ax=b. Hence, x1=b.
x2−x1=−r2+β(x1−x0)=(b−Ax2)+βx1
x2(I+A)=b+(1+β)x1=b+(1+β)b=2b+βb
x2=b(2+β)
Similarly, if we consider x3, we get a polynomial of A2b, Ab and b. And so on.
Hence, in case of xi we are working with a space of vectors [Ai−1b,Ai−2b,...,Ab,b]
This space is called Krylov space and is useful in related problems, such as numeric eigenvector/eigenvalue
estimation. Such problems are often solved with a related family of algorithms, such as Arnoldi iteration and Lanczos
algorithm.
TODO: fix bugs
Convergence rate: inexact arithmetic
If we allow for a certain error, conjugate gradients might not even require N iterations. Consider the following
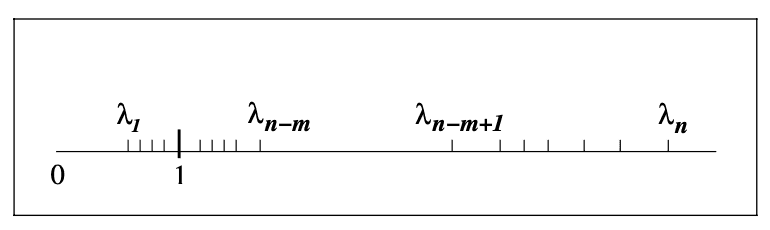
clustering of eigenvalues of our matrix A:
Two clusters of eigenvalues. From Nocedal-Wright’s Numerical optimization.
Recall the convergence rate formula: ∣∣xn−k−x∗∣∣A≤(λn−k+λ1λn−k−λ1)2∣∣x0−x∗∣∣A.
Suppose that we’ve already made m+1 iterations. Then λn−(m+1)−λ1 is very small and λn−(m+1)+λ1≈2λ1.
Hence, ∣∣xn−k−x∗∣∣A≤ϵ, where ϵ>0 is small, and we’ve basically converged to the solution.
Preconditioning and clusters of eigenvalues
If the matrix A is ill-conditioned, iterative multiplication of a vector b by a matrix A would accumulate
the floating point rounding errors, resuling in a failure to converge to the correct solution. Hence, we need to
“normalize” the matrix A similarly to how we apply batch norm or layer norm to normalize the layers of neural networks.
This process is called pre-conditioning. We are multiplying both sides of our equation by a pre-conditioner matrix P:
PAx=Pb.
An ideal pre-conditioner would convert our matrix to a perfect sphere. Then pre-conditioning axes should be the
eigenvectors and coefficients be eigenvalues. So, the perfect pre-conditioner is the matrix inverse. However, this is
computationally impractical, as it is more-or-less equivalent to the solution of the initial system Ax=b and would
take O(N3) operations.
The simplest pre-conditioner matrix is a diagonal matrix of the values at the diagonal of the matrix A. This is called
Jacobi pre-conditioner. It is
equivalent to scaling the matrix along the coordinate axes by values at the diagonal of matrix A. Obviously, this is
an imperfect solution.
A more practical pre-conditioner would be an incomplete Cholesky decomposition. I will first discuss a regular Cholesky
decomposition in the context of conjugate directions, and then its sparse variation.
Cholesky decomposition as a special case of conjugate directions
Cholesky decomposition is a representation of our matrix A as a product of lower-diagonal matrix L and its transpose
upper-diagonal matrix LT: A=LLT.
One can see that the vectors of inverse of Cholesky decomposition are actually conjugate directions of matrix A, such
that the first direction is parallel to the first coordinate axis, second direction is in the plan of the first two
axes etc. Consider an upper-triangular matrix V:
VTAV=I
VTA=V−1
A=V−1TV−1
Now we can denote L=(V−1)T and LT=V−1, and we get A=LLT.
To see that inverse of an upper-triangular matrix is upper-triangular, just apply the textbook method of matrix
inversion, i.e. write down a matrix and a unit matrix next to each other, Gauss-eliminate the left, and you will
obtain its inverse from the right:
This approach is known as IC(0). If you want more precision and less sparsity, you can take the sparsity pattern of
A2, which has less 0 elements, and calculate Cholesky decomposition for it. This would be called IC(1). And so on,
then it would be called IC(k). Greater k would result in a better pre-conditioning at the cost of more compute.
If the matrix A is not sparse at all, we can employ IC(τ) approach: choose some threshold of absolute
value of an element of matrix A, called τ and if the element is smaller than that, consider it 0. Thus, we achieve
a sparse matrix with a Frobenius norm more or less close to the original matrix A. Hence, we get a reasonable
pre-conditioner at an O(N2) compute and O(N) memory cost.
Written by Boris Burkov who lives in Moscow, Russia, loves to take part in development of cutting-edge technologies, reflects on how the world works and admires the giants of the past. You can follow me in Telegram